话说之前对代码的编写大多都是直接使用jdk里面的对象,有时候也对一些对象直接封装之后就使用了,很少去了解源码中具体细节是怎么实现的,这样显然不符合我这么帅的人的做事风格,所以我现在就来对源码进行学习学习,可能篇幅略长,不过会慢慢记录下我学习的过程和总结一下,希望对自己有帮助的同时,也能够帮助到和我一样,希望更进一步去理解java的小伙伴们!!
String类的大概面貌
废话不多说了,先打开我的 InteliJ IDEA , 创建一个学习源码的项目,就叫做「learnJavaSourceCode」吧。
打开String.java之后可以发现了String实现了java.io.Serializable, Comparable
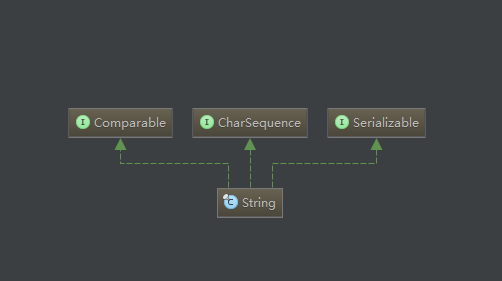
在 String 类中有4个成员变量:
1 | 1. private final char value[]; |
有一个内部类CaseInsensitiveComparator,还有其它就是构造函数和方法了!
String的概要描述总结
也就是在一开始的一大段注释:
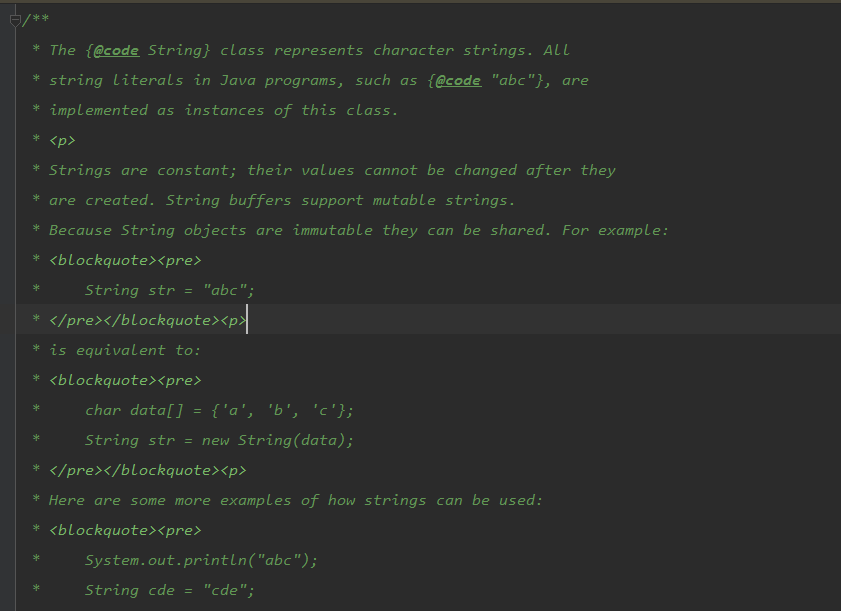
我对它总结一下就是以下几点:
在java中所有的字符字面值(例如:”abc”)都是 String 的一个实例;
Strings是常量,它们的值在被创建之后就不可以改变了,字符缓冲支持改变,因为 String 的对象是不可变的,所以它们可以被共享;
String包含了一些方法,例如字符的大小写转换等(有点废话 - -);
java语言提供了支持字符间的连接操作和将对象转化为字符串的操作,字符间的连接是通过 “+” 来操作的,它们之所以可以连接是因为通过 StringBuffrer 或者 StringBuilder 的 append 方法实现的,而将对象转化成字符串是通过 Object 方法中的 toString 方法。
携带 null 这个参数给String的构造函数或者方法,String会抛出NullPointerException,这不是见惯不惯了吗:)
String 表示一个 UTF-16 格式的字符串。其中的 增补字符 由 代理项对 表示,索引值是指 char 代码单元,因此增补字符在 String 中占用两个位置。
对String的主要描述进行演示
- 在java中所有的字符字面值(例如:”abc”)都是 String 的一个实例:
很好理解,我们经常就是这样做的,java这么规定,我们也就这么写了:
1 | String s = "abc"; //这里的 "abc" 就是一个对象 |
Strings是常量,它们的值在被创建之后就不可以改变了,字符缓冲支持改变,因为 String 的对象是不可变的,所以它们可以被共享:
那是不是这样:
1 | public static void main (String[] args){ |
奇怪,不是说不能被改变了吗?为毛可以是def?
其实不然,我们一开始是创建的 “abc” , 我们从1中 「在java中所有的字符字面值(例如:”abc”)都是 String 的一个实例」 可以知道,其实”abc”就是一个String的实例,我们的String s 只不过是指向这个”abc”的String对象了,而我们的 s = “def” 则是将s指向”def”这个对象!
心情好,画个图吧:
首先我们写了这样一句 String s = “abc”; 那么是这样的:
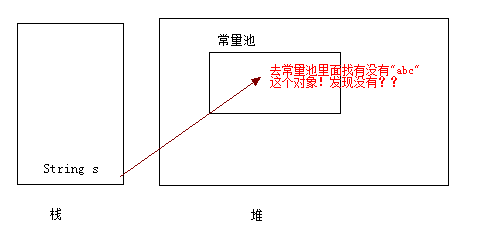
s 这个引用会去常量池里面找有没有”abc”,发现卧槽,没有,那么就创建一个:
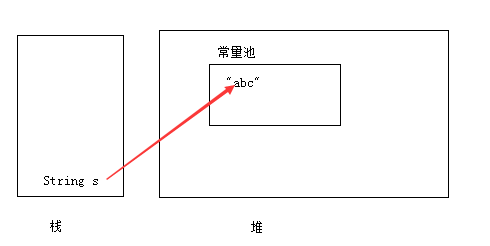
这时候 s 就可以指向 “abc” 了!
接着我们把 s = “def” , 同样的道理,它会去常量池找有没有 “def”, 有就指向它,没有就在常量池创建一个:
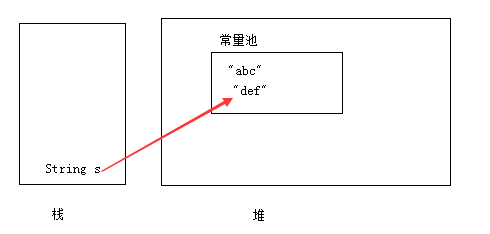
所以我们现在应该知道 「String的对象是不可变的,所以它们可以被共享」 这句话是什么意思了吧 - -
Java语言提供了支持字符间的连接操作和将对象转化为字符串的操作,字符间的连接是通过 “+” 来操作的,它们之所以可以连接是因为通过 StringBuffrer 或者 StringBuilder 的 append 方法实现的,而将对象转化成字符串是通过 Object 方法中的 toString 方法。
写段代码:
1 | String s1 = "I "; |
运行后理所当然是 I Love You :)
接着使用jad反编译下上面这段代码会发现:
1 | String s1 = "I "; |
可以看到它真的用StringBuilder对象用append方法把我们的s1 + s2 + s3 拼接起来了,然后用toString方法得到 I Love You … 害羞 - -
对String常用构造方法解析
String(String original);
首先来个问题思考:
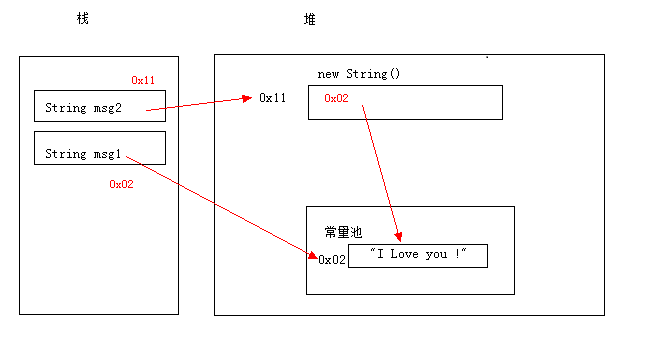
1 | String msg1 = "I Love You !" ; |
上面的 msg1 和 msg2 是一样的吗? (我们不一样~~)
我们已经知道msg1是从常量池去取的,而我们new String() 这时候应该在堆内存产生一个String对象,而通过源码可以看到这个String对象方法是将我们传入的这个 “I Love You !” 对象的value和hash进行复制:
1 | public String(String original) { |
画个图那就是这个样子的:
String(char[] value)
我们创建个char[],然后传给String构造函数:
1 | char[] c = new char[3]; |
通过debug后可以发现:

原来它通过 Arrays.copyOf 把我们的char直接复制给value了!
其实我们应该也猜到了,String里面的value就是char数组!
String(byte[] bytes)
String提供了好几个含有byte[]参数的构造函数,那么我们对byte[]和String间的转化就容易许多了。
可能你之前应该遇到过乱码问题,你应该是这么解决的:
1 | try { |
其实String里面是含有一个char[]来存放这些字符,而这些字符是以Unicode码来存储的,字节是通过网络传输信息的单位,所以我们在传入byte[]转化为String的时候,是需要对其进行编码的:
1 | static char[] decode(String charsetName, byte[] ba, int off, int len) |
对String常用方法解析
charAt(int index)
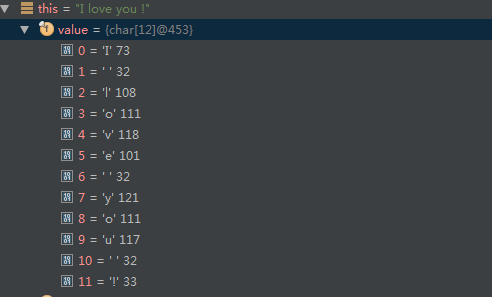
1 | String msg = "I love you !"; |
可以看到这个方法是根据索引返回Char值!
进去源码看看:
1 | public char charAt(int index) { |
可以看到当我们传进去的索引值是小于0 或者 大于 这个字符串的长度,就会抛出异常。否则就返回value数组中对应的值!
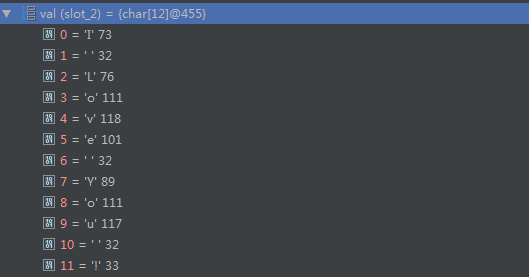
通过 debug 可以看到其实我们刚刚定义的 String msg = “I love you !” 中的值被放到了 value 这个数组中了!

而我们 char c = msg.charAt(3) 传入的这个3 就是这个数组对应的下标3,所以呢,输出就是o啦!
equals(Object anObject)
equals我们通常用于比较是否相同,那么你知道下面这段代码分别输出的是什么吗?
1 | String s = "I Love You !"; |
他们分别输出的:
- true
- true
- false
- true
可能有些人会奇怪会什么 s == s2 是false? 他们不是都是是 “”I Love You !” 吗?
这时候我们就要来看看 == 和 equals 的区别了!
其实 == 比较的是他们的地址值(hashcode),我们知道String是不可变的,我们可以知道s 和 s1 指向的都是 “I Love You !”;所以他们的hashcode是一样的。所以返回true;而s 和 s2 他们指向的地址是不一样的所以是false;
可能此刻有人会疑惑那么为什么s.equals(s2)返回的是true了。这时候我们应该可以猜到equals应该判断的不是两个对象间的hashcode吧,我们看下源码:
1 | public boolean equals(Object anObject) { |
很明显我们可以发现,equals判断的不是hashcode,而是判断它们的值是否相同,所以s.equals(s2)返回的是true!
endsWith(String suffix)
有时候我们可能会判断字符串是否以指定的后缀结束。例如我们有获取的图片路径,判断他是不是以.jpg结尾的:
1 | String s = "canglaoshi.jpg"; |
debug一下就明白了它是怎么判断的:
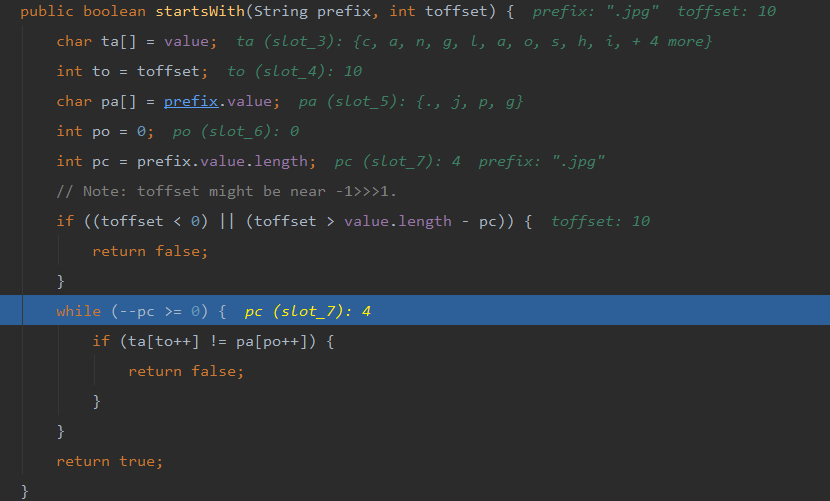
它会去调用 startsWith 方法。
- 用 ta[] 这个数组来存放 “canglaoshi.jpg”;
- 用 int to 来接收 “canglaoshi.jpg”的长度(14) 减去 “.jpg” 的长度(4) = 10;
- 用 pa[] 来存放 “.jpg”;
- 用int pc 来接收 “.jpg”的长度;
最后就是以pc为次数进行遍历ta[]从下标为to开始,pa[] 从下标为0开始逐一判断,如果相同就返回true!
replace(char oldChar, char newChar)
返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。
那么问题来了,下面这一段输出的是什么呢?
1
2
3String s = "I Love You !";
s.replace("Love", "Fxxk");
System.out.println(s);
如果你说是 I Fxxk You !, 那就真的是欠fxxk了~ 别忘了,String 是不可变的。所以呢,
s 还是 I Love You, 而String s1 = s.replace(“Love”, “Fxxk”); 这样的s1 才是
“I Fxxk You !”
hashCode()
返回此字符串的哈希码。
哈希码是怎么算出来的?
1 | System.out.println("I Love You !".hashCode()); //-1710377367 |
我们知道我们的 “I Love You !” 被放到了char数组中。
hashcode的算法是这样的:
1 | 31 * 0 + val[0] |
它的代码实现是:
1 | public int hashCode() { |
可以看到它的算法,其中char值就是字符对应的ACII编码:
substring(int beginIndex)
返回一个新的字符串,它是此字符串的一个子字符串。
可以理解为截取字符串,它的实现就是用数组的copyOfRange将指定数组的指定范围复制到一个新数组:
1 | this.value = Arrays.copyOfRange(value, offset, offset+count); |
