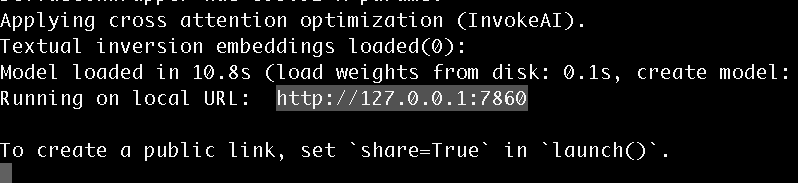
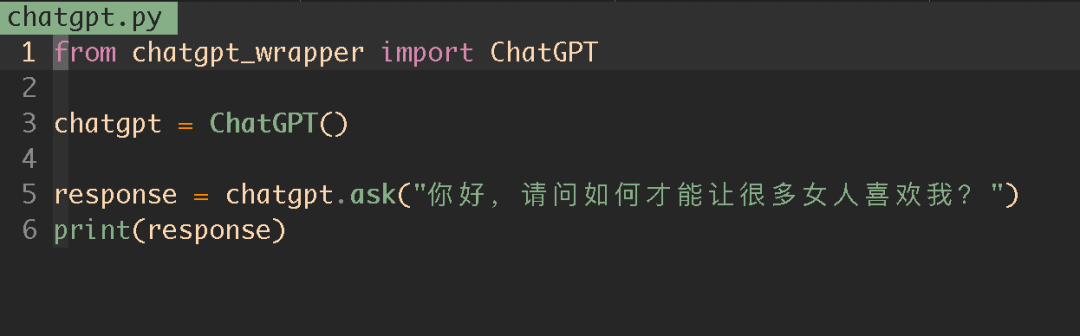
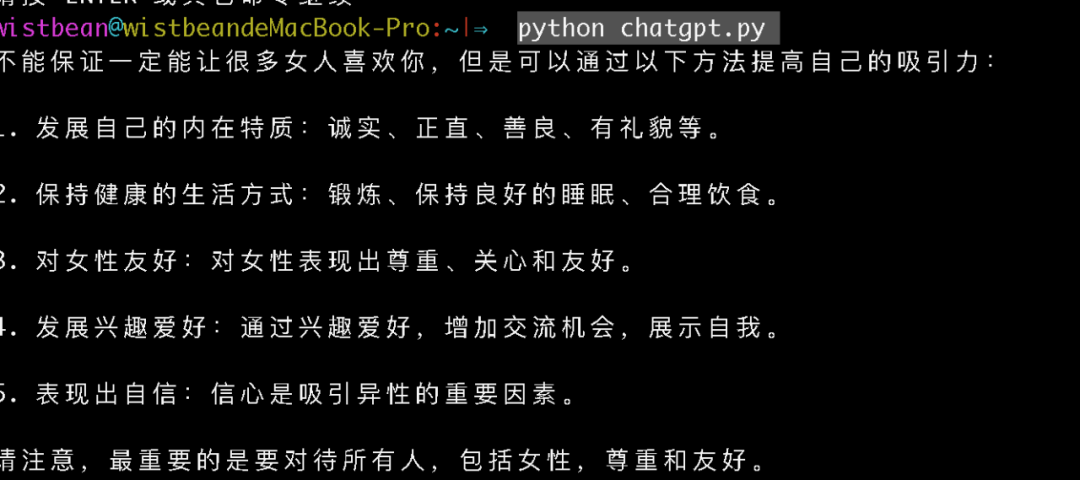
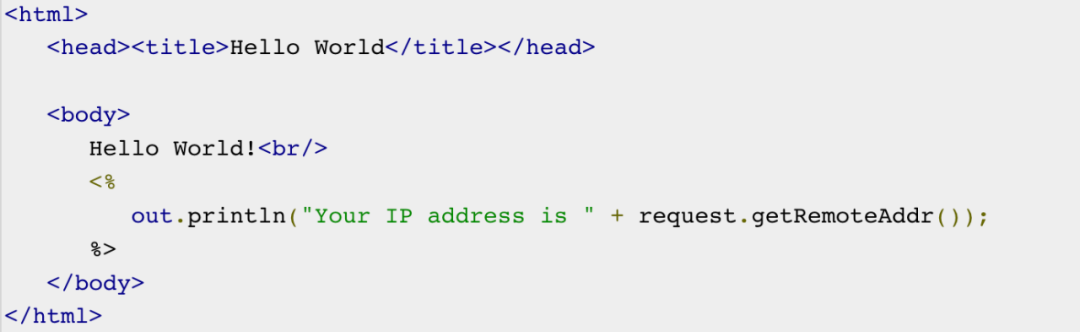
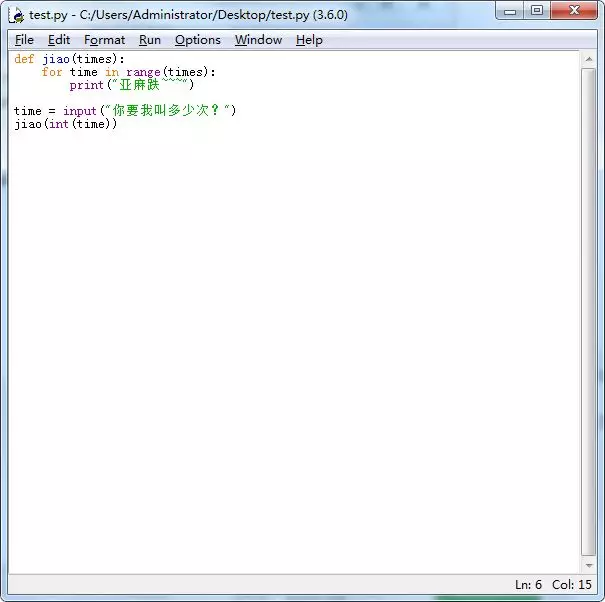
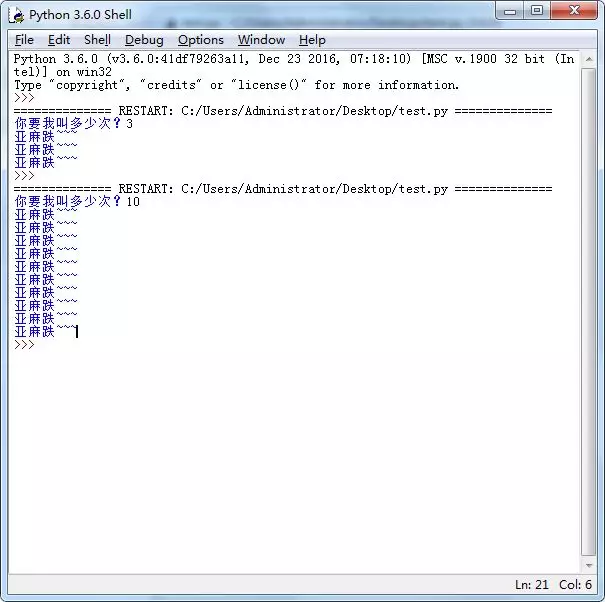
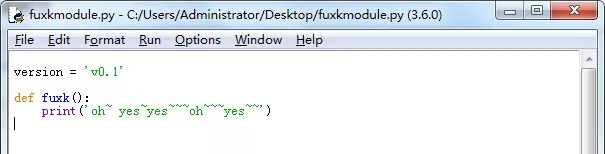
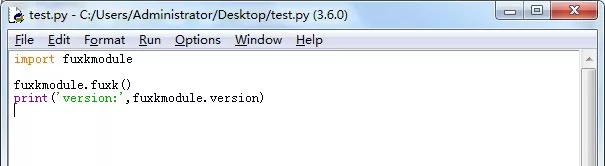
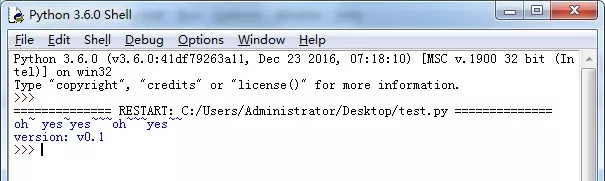
python scripts/txt2img.py –prompt “a professional photograph of an astronaut riding a horse” –ckpt <path/to/model.ckpt/> –config <path/to/config.yaml/>
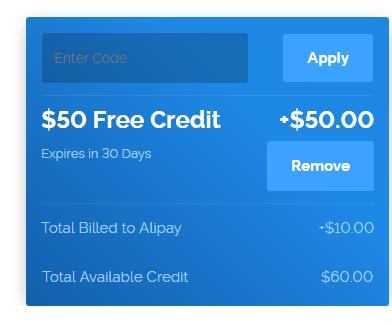
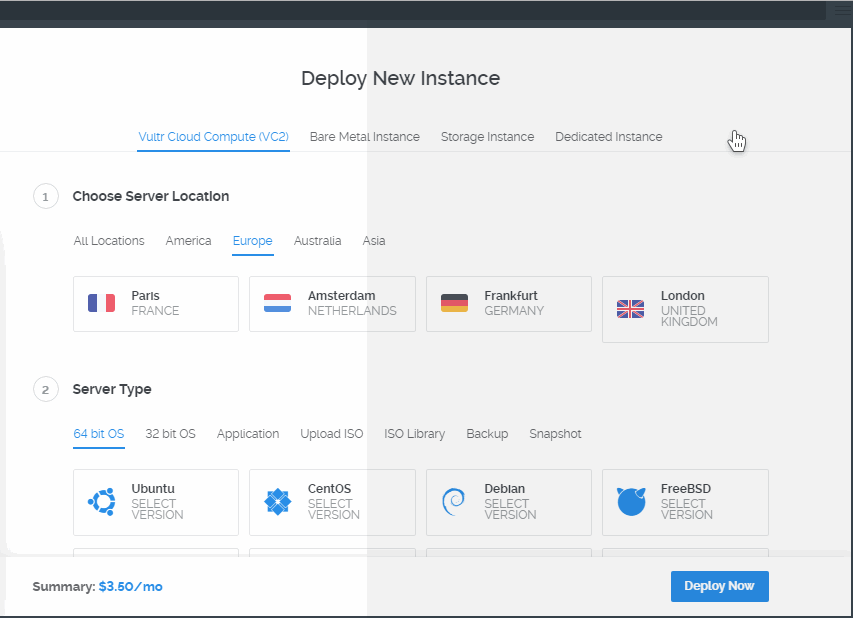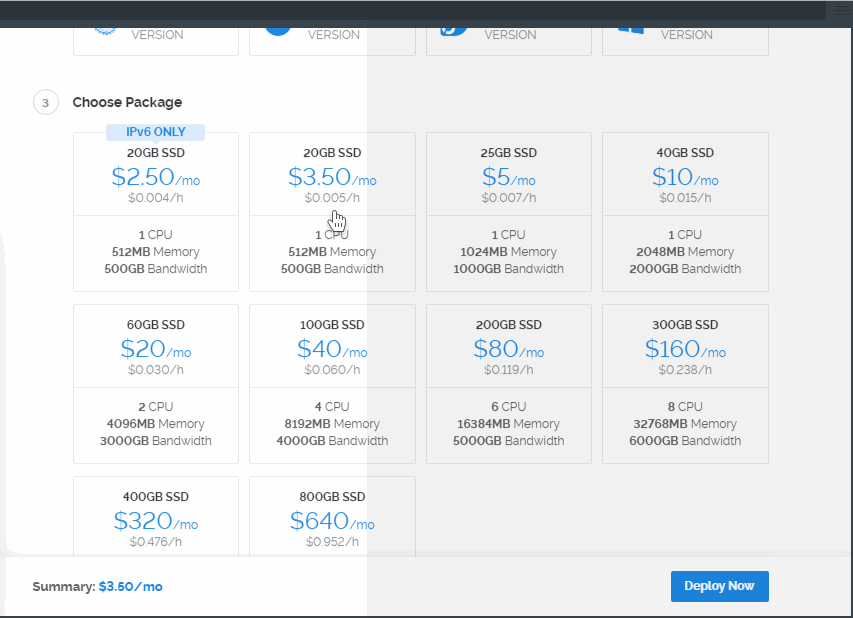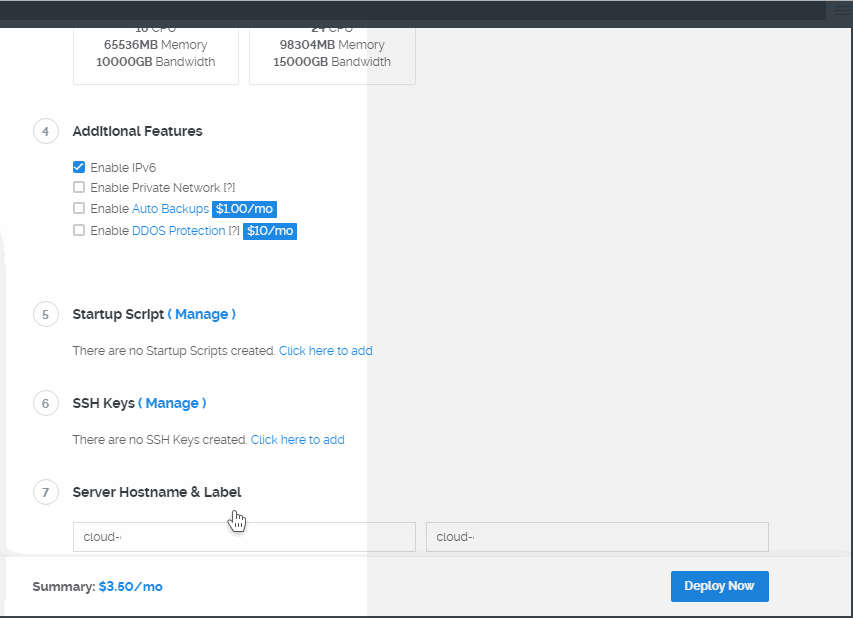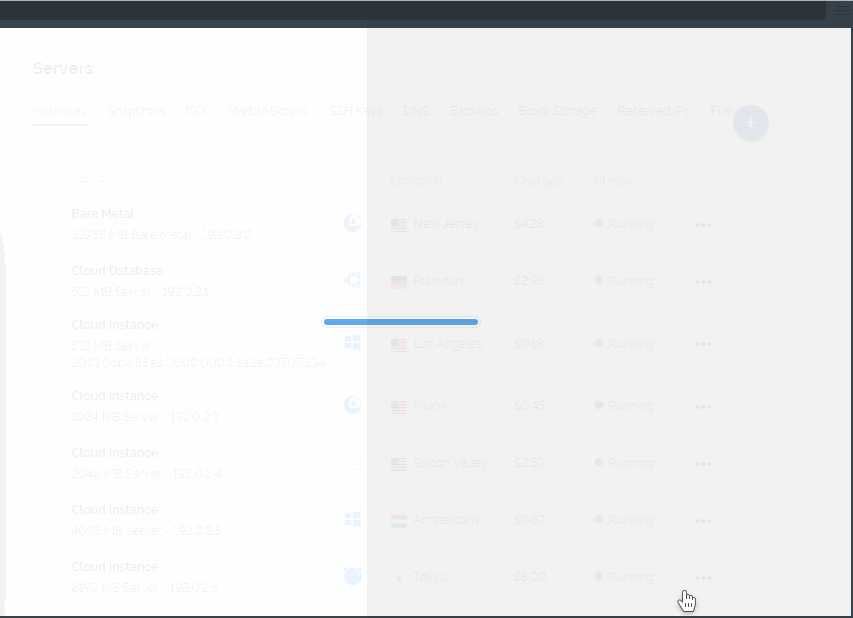
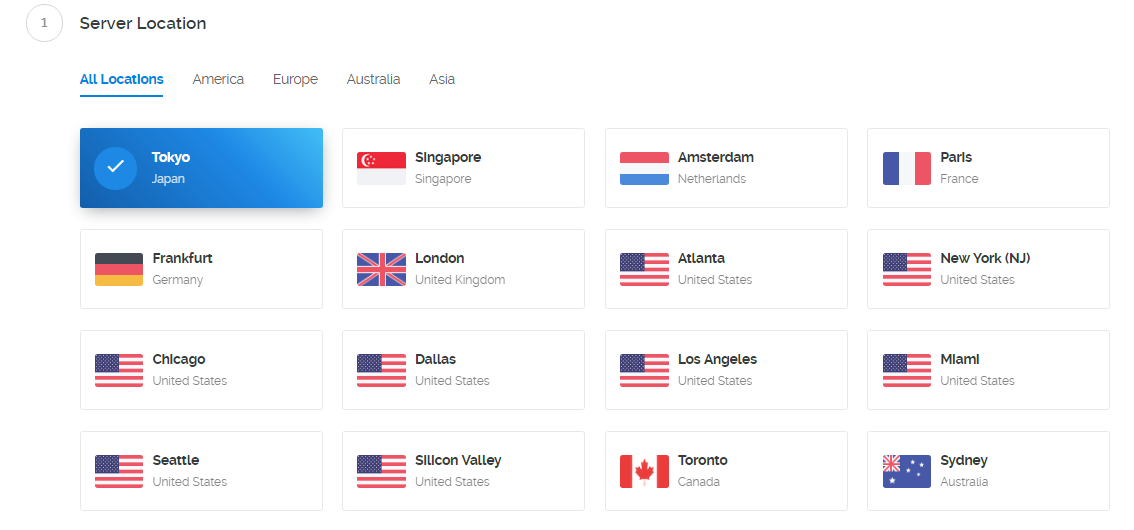
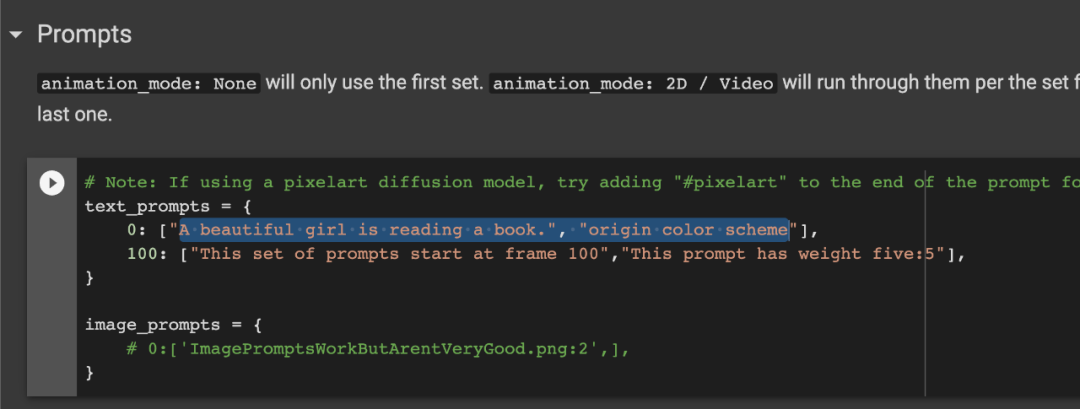
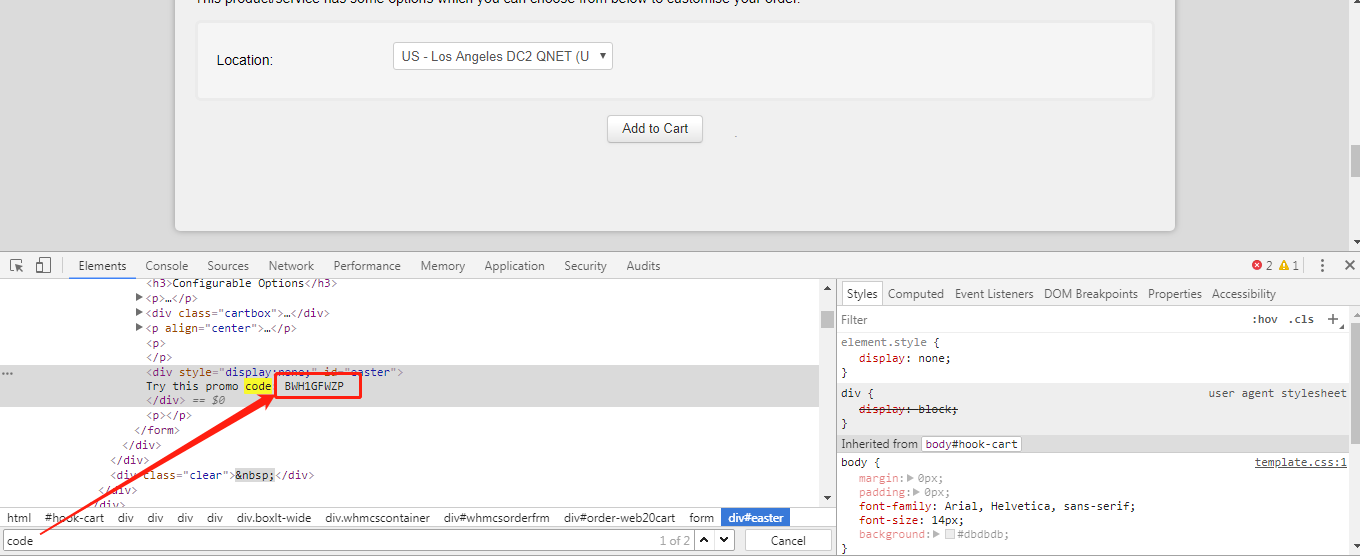
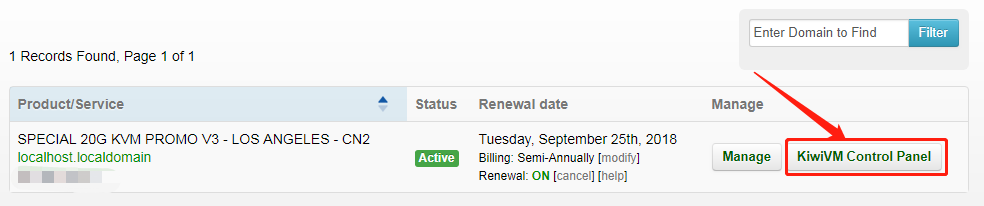
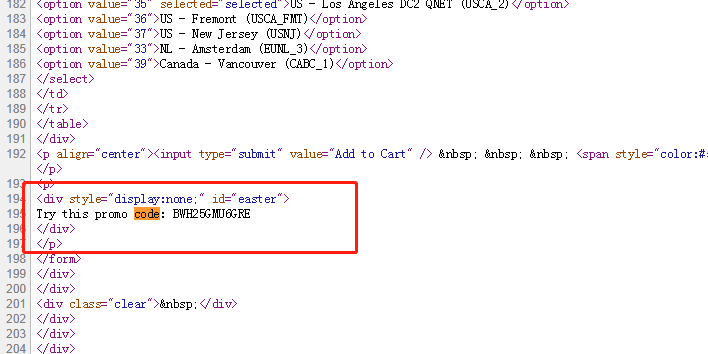
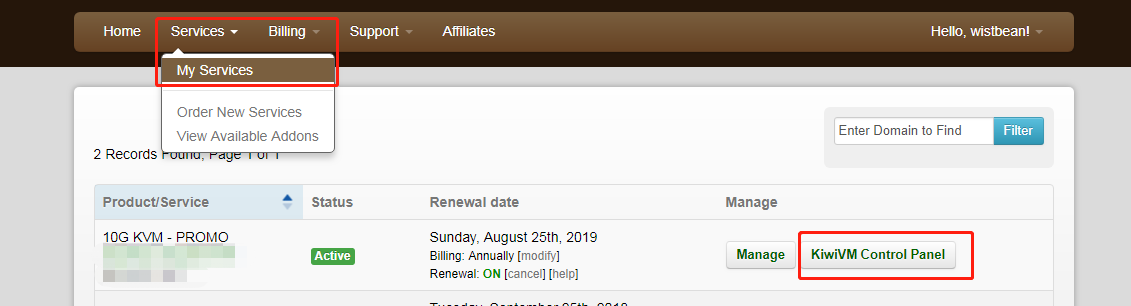
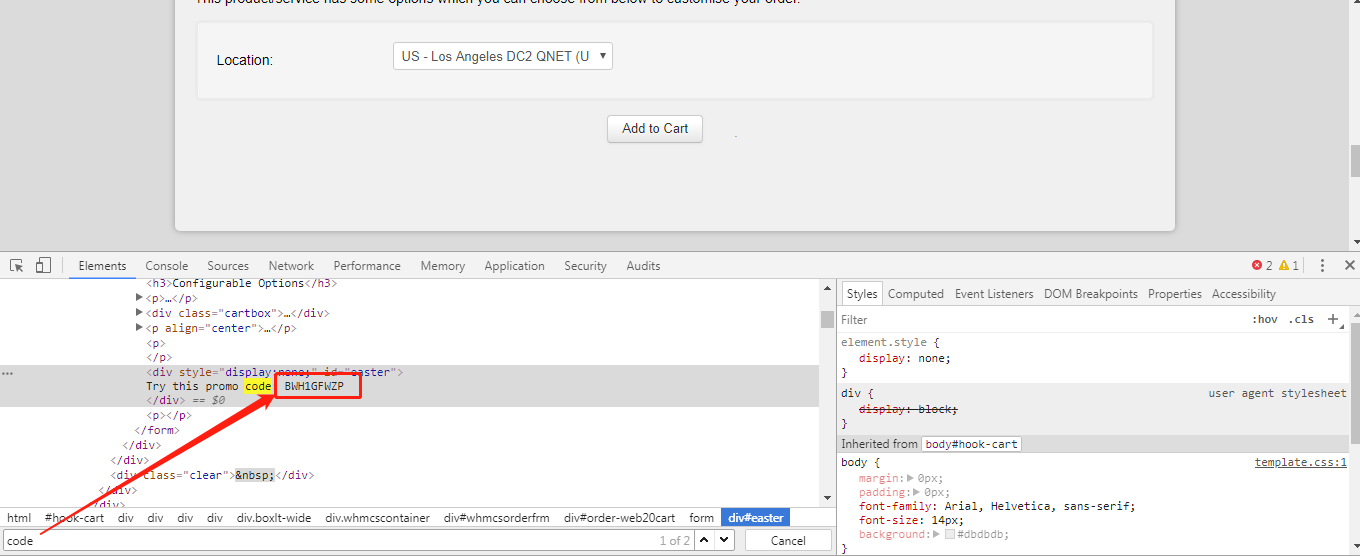
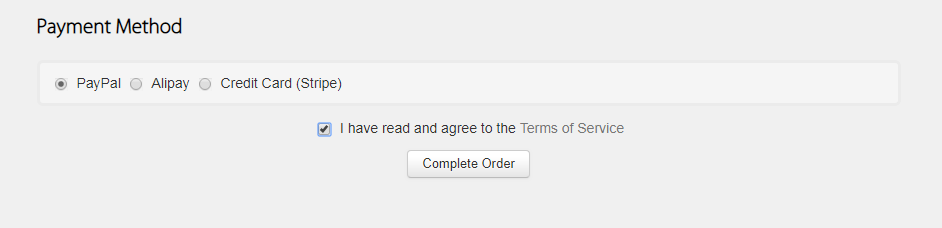
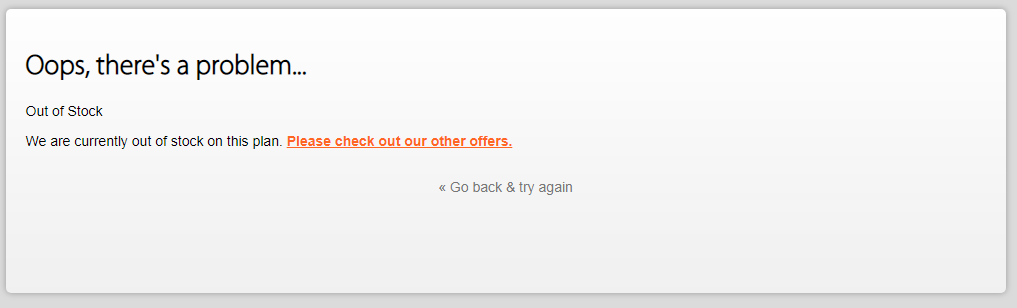
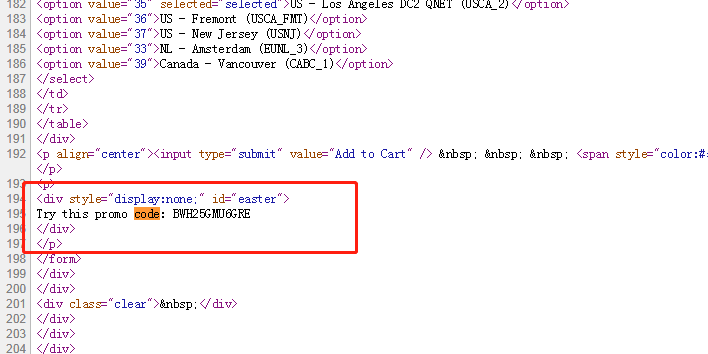
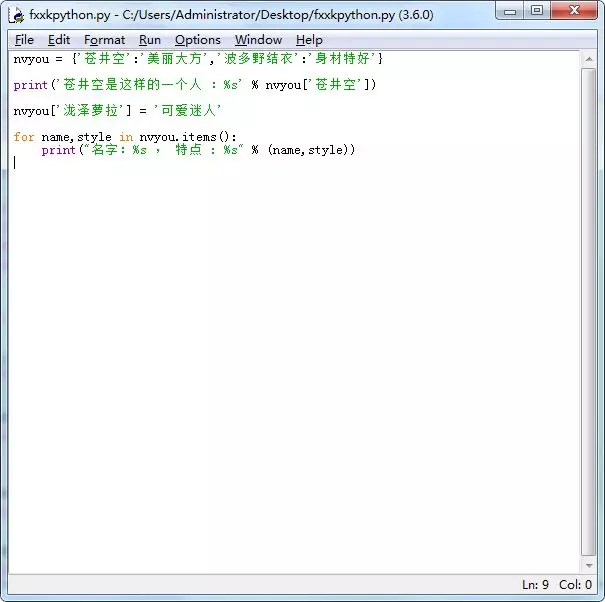
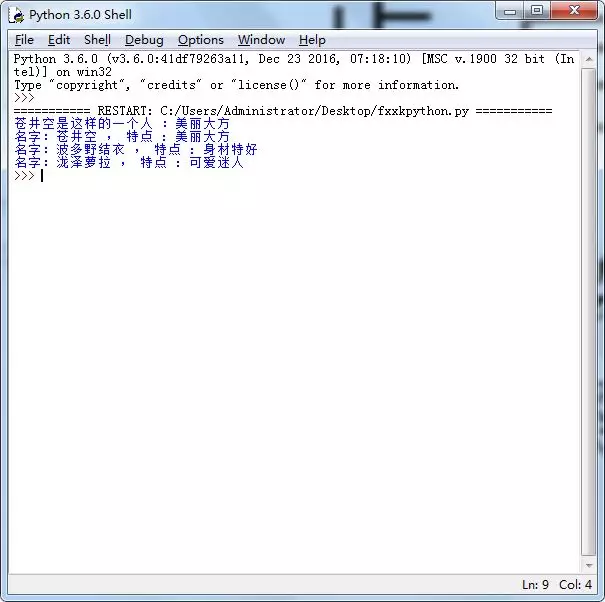
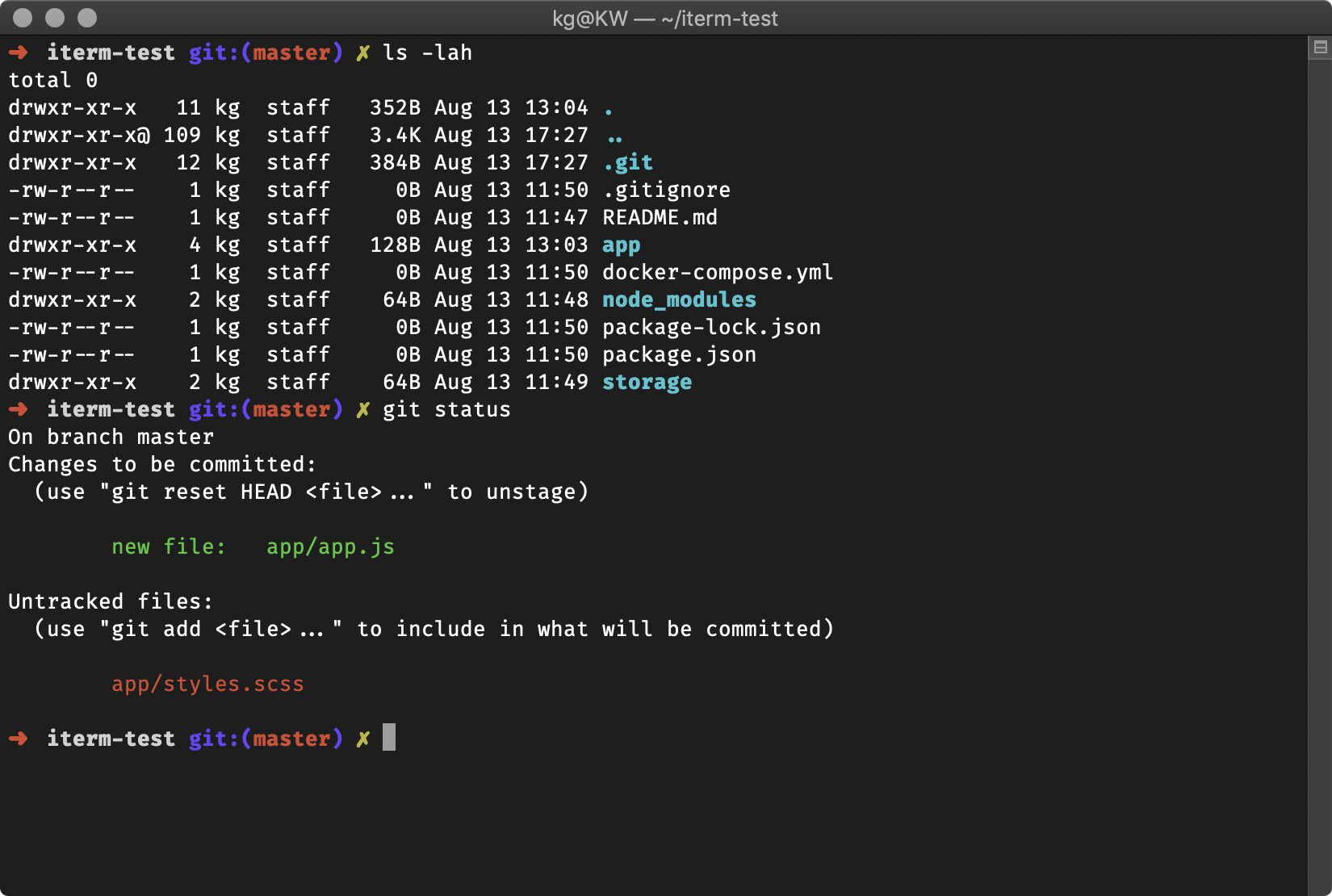
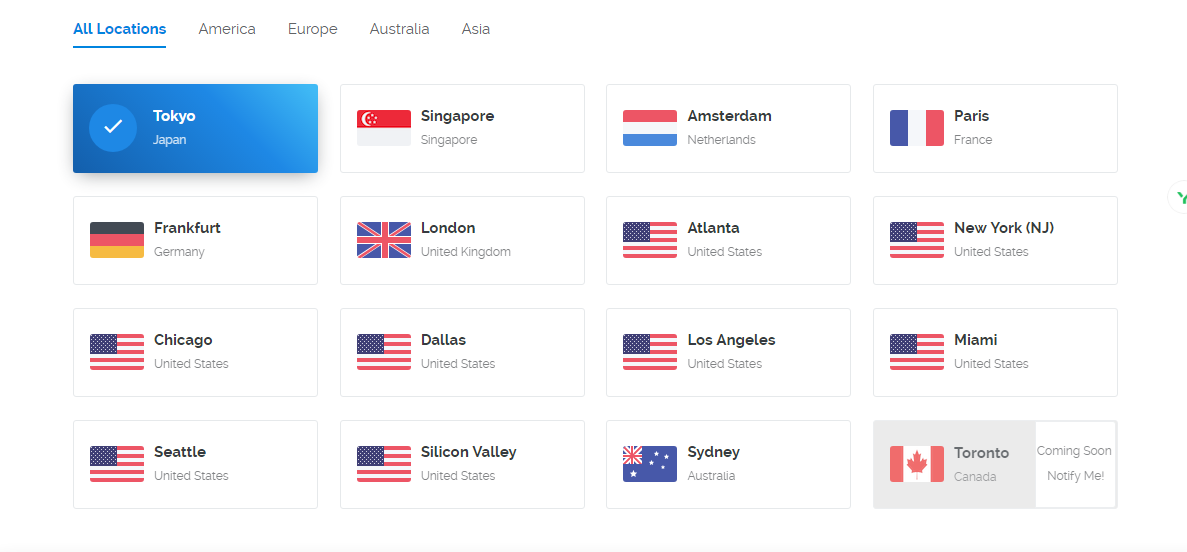
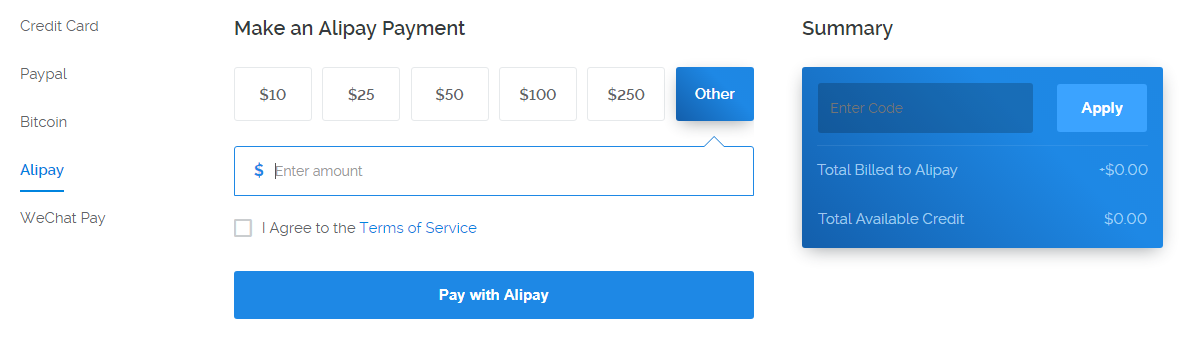
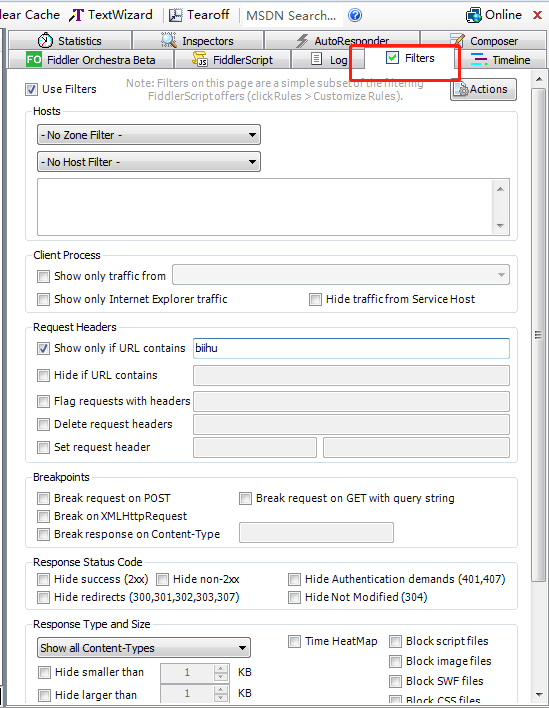
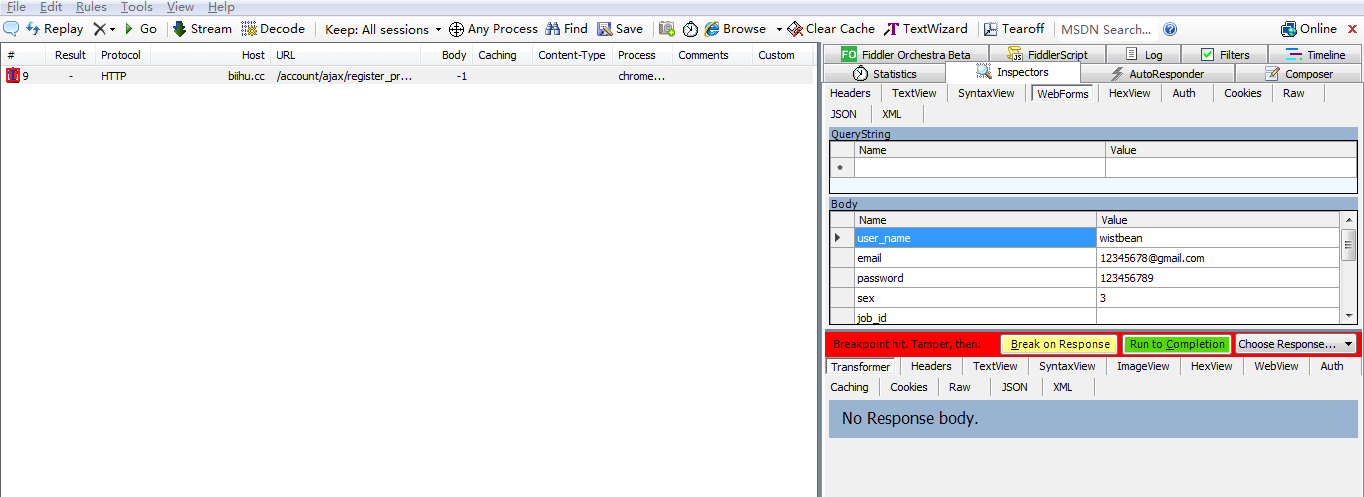
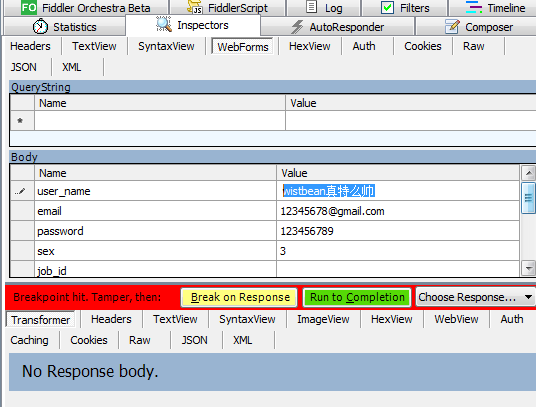
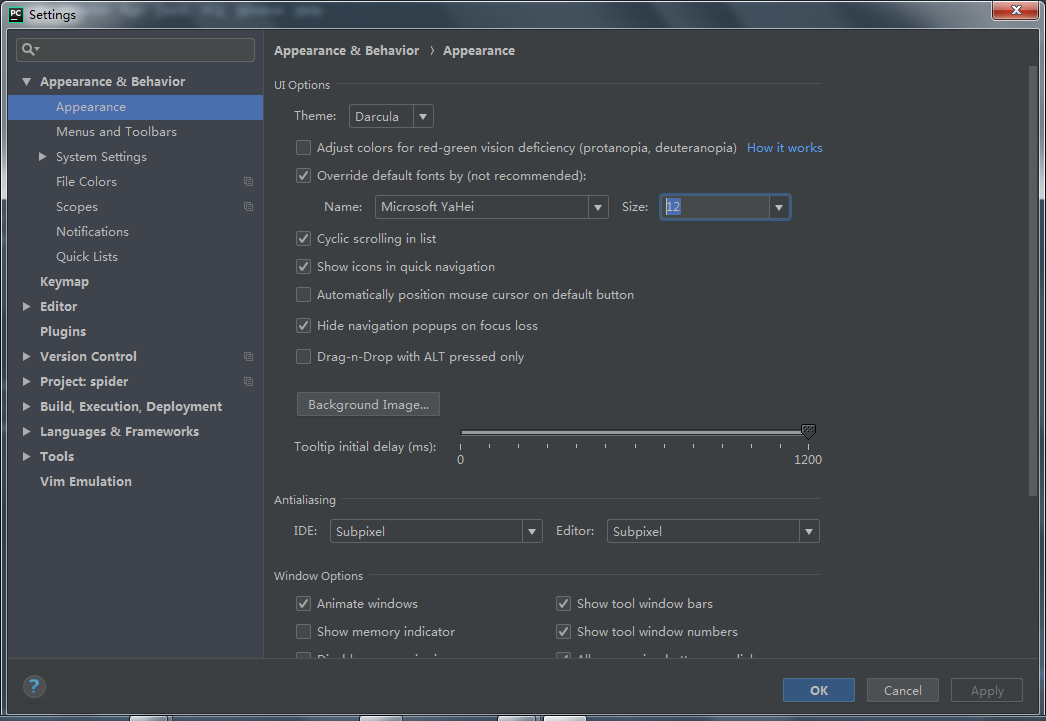
当你进到这个页面的时候呢,别急着点击「Add to Cart」添加到购物车,这里面暗藏着一个优惠码,很多人不知道,使用浏览器查看源代码,chrome浏览器的话按F12,然后搜索「code」,你会发现有一个 「Try this promo code: xxxx 」,这个xxxx就是优惠码,你把他复制下来,待会有用。
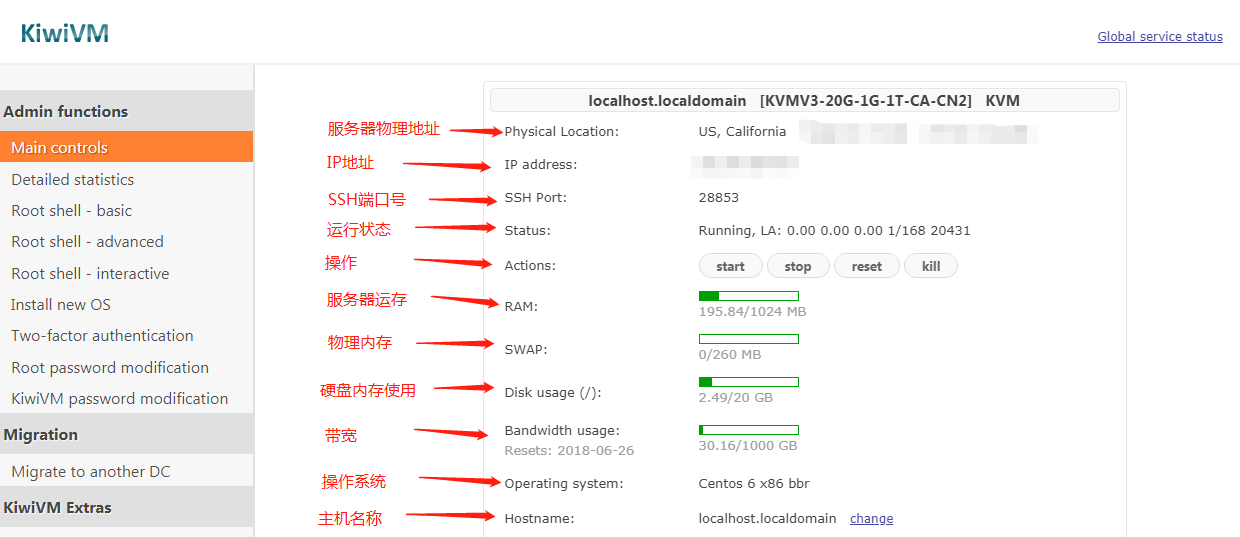
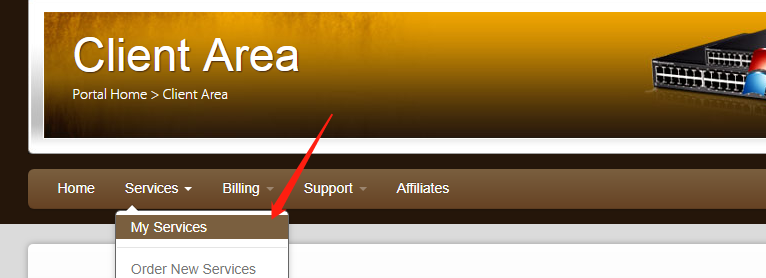
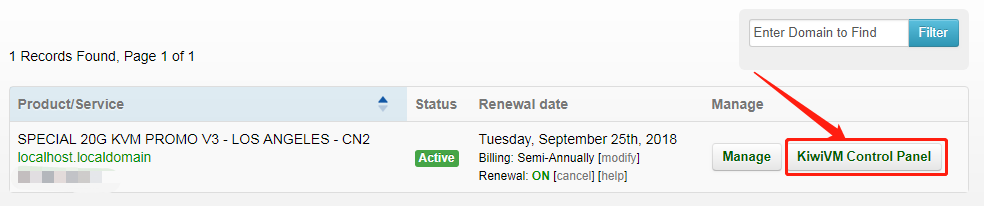
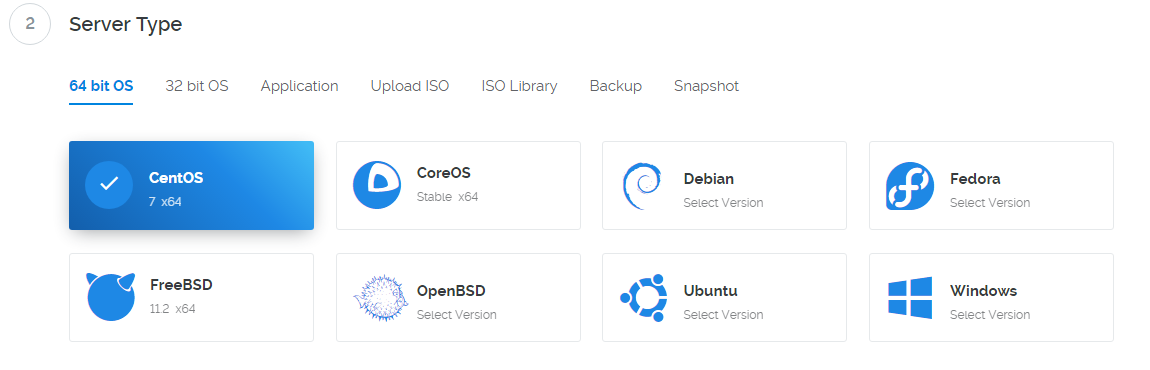
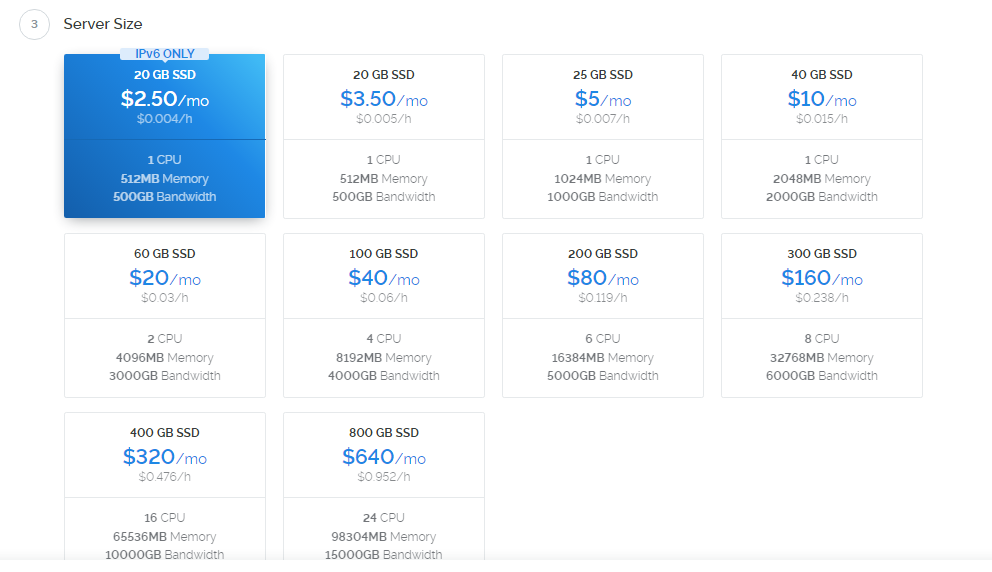
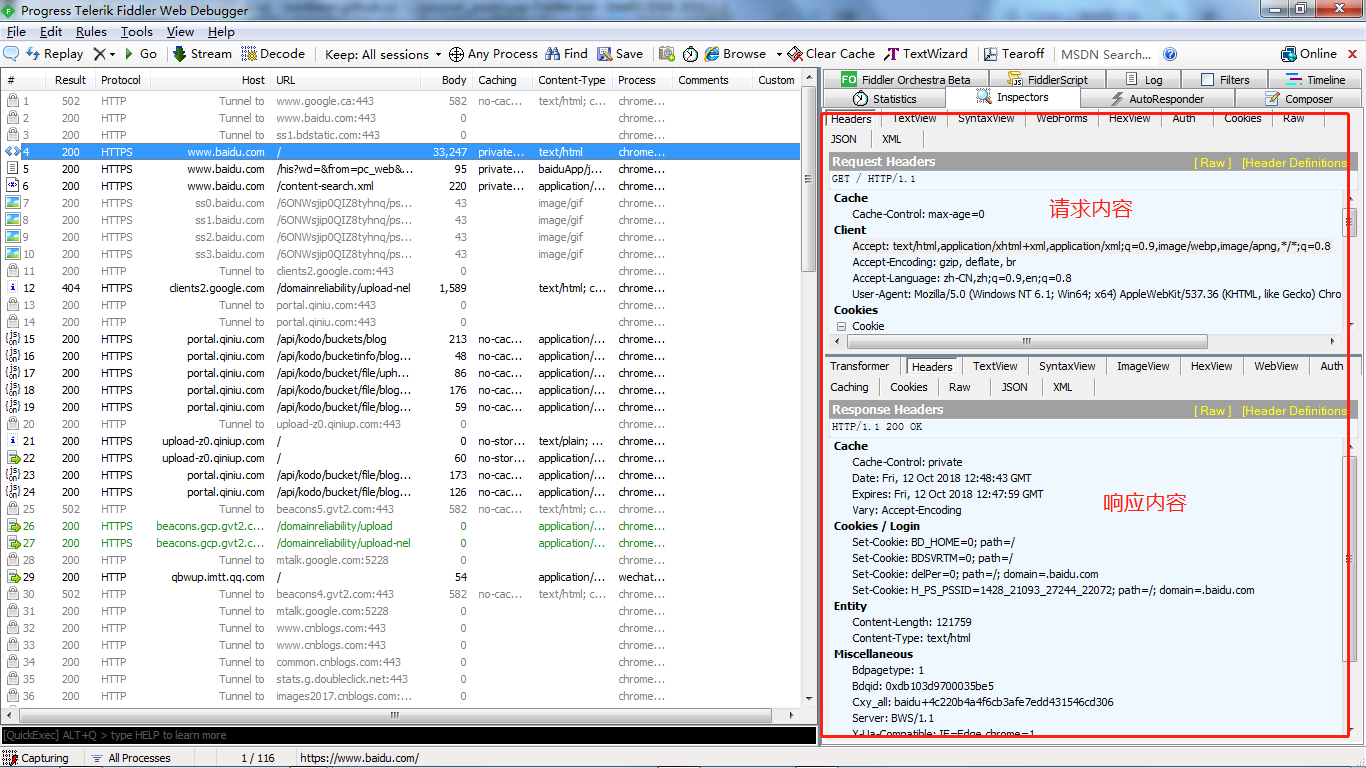
使用搬瓦工搭建VPN
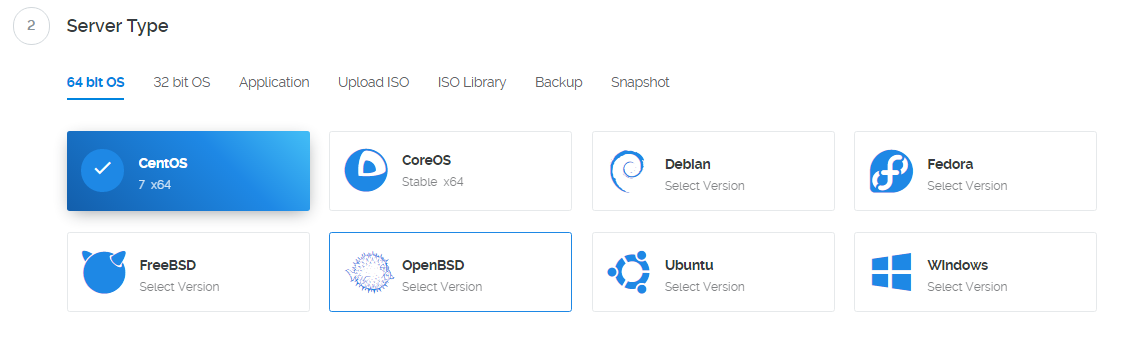
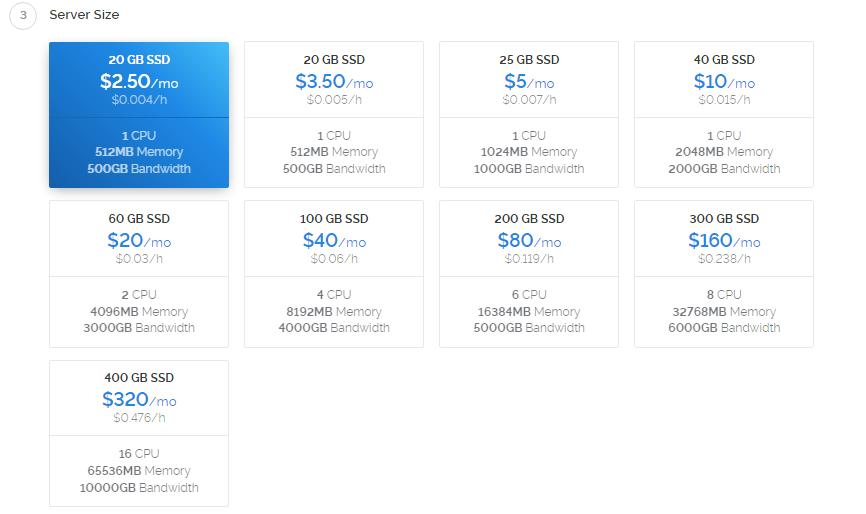
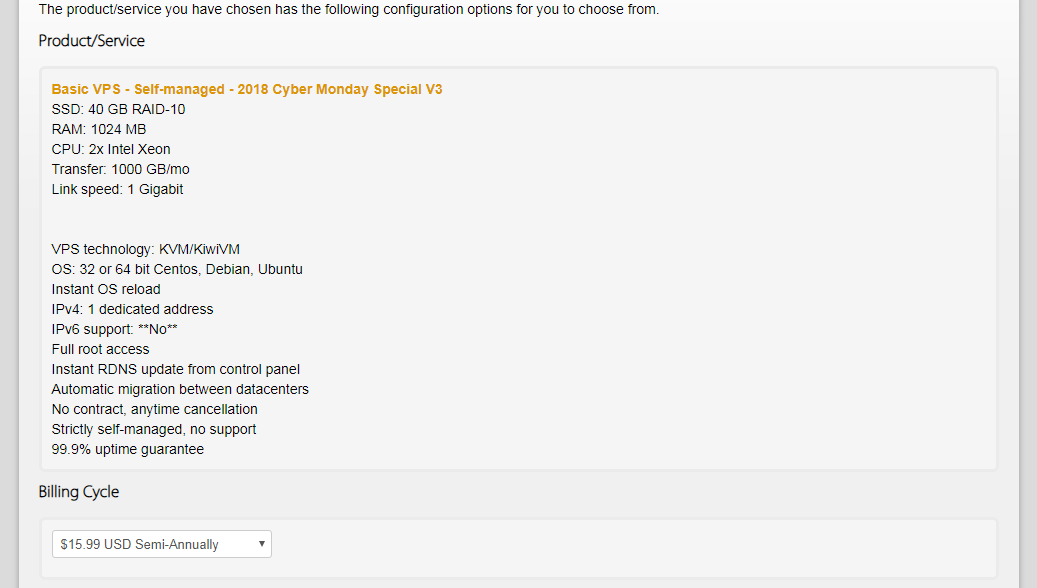
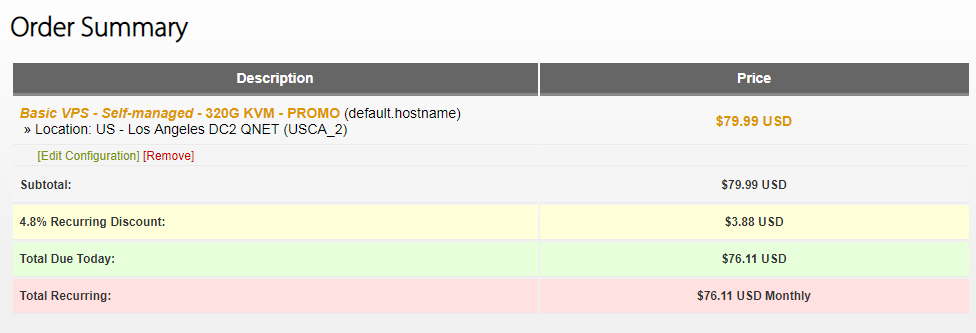
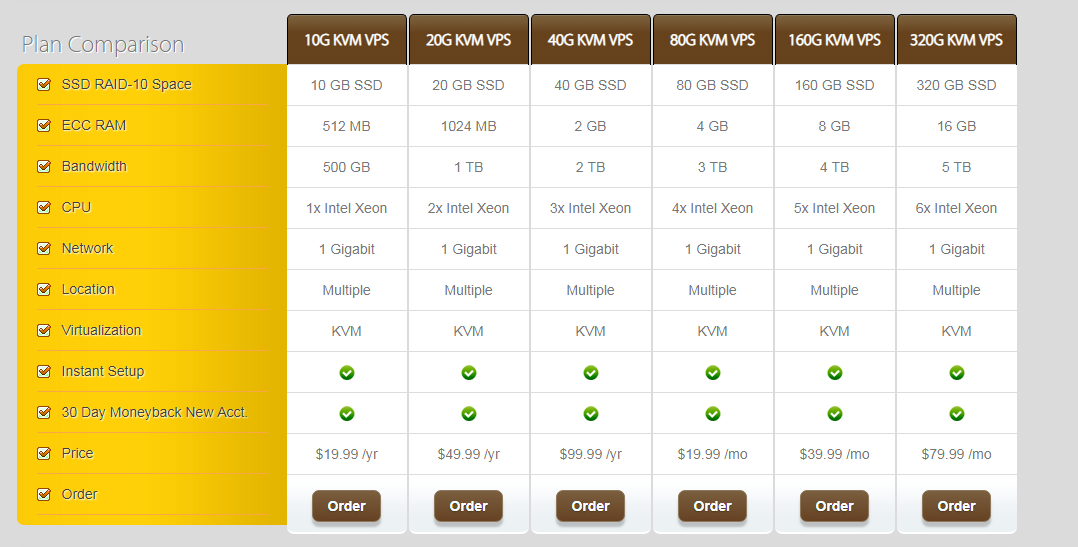
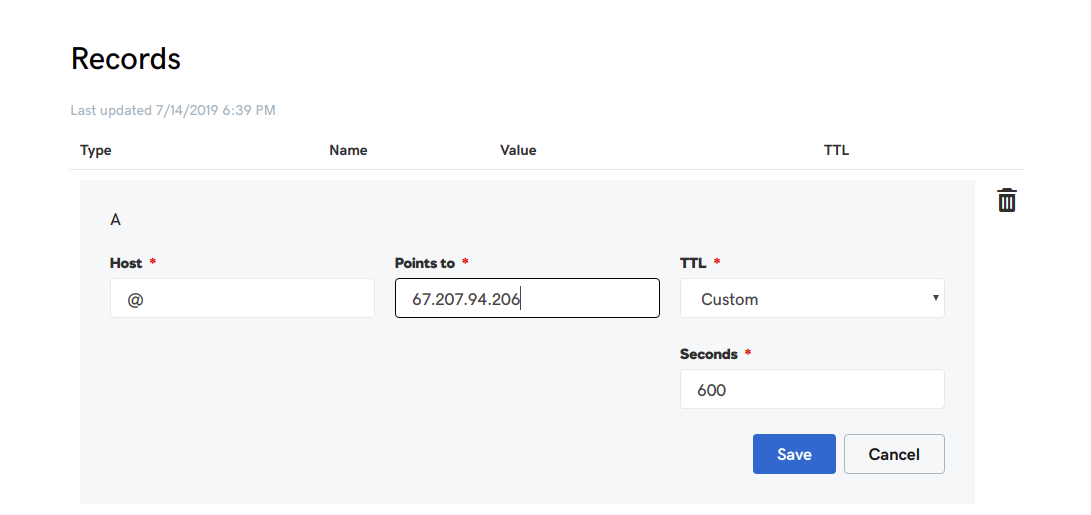
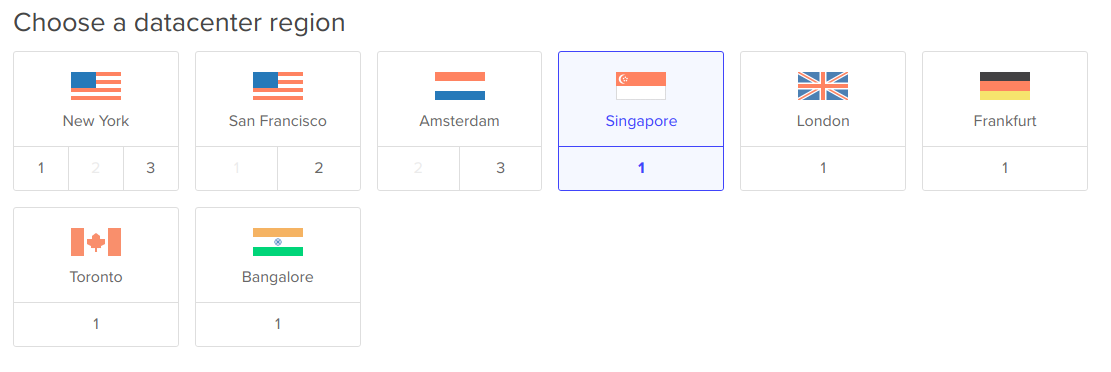
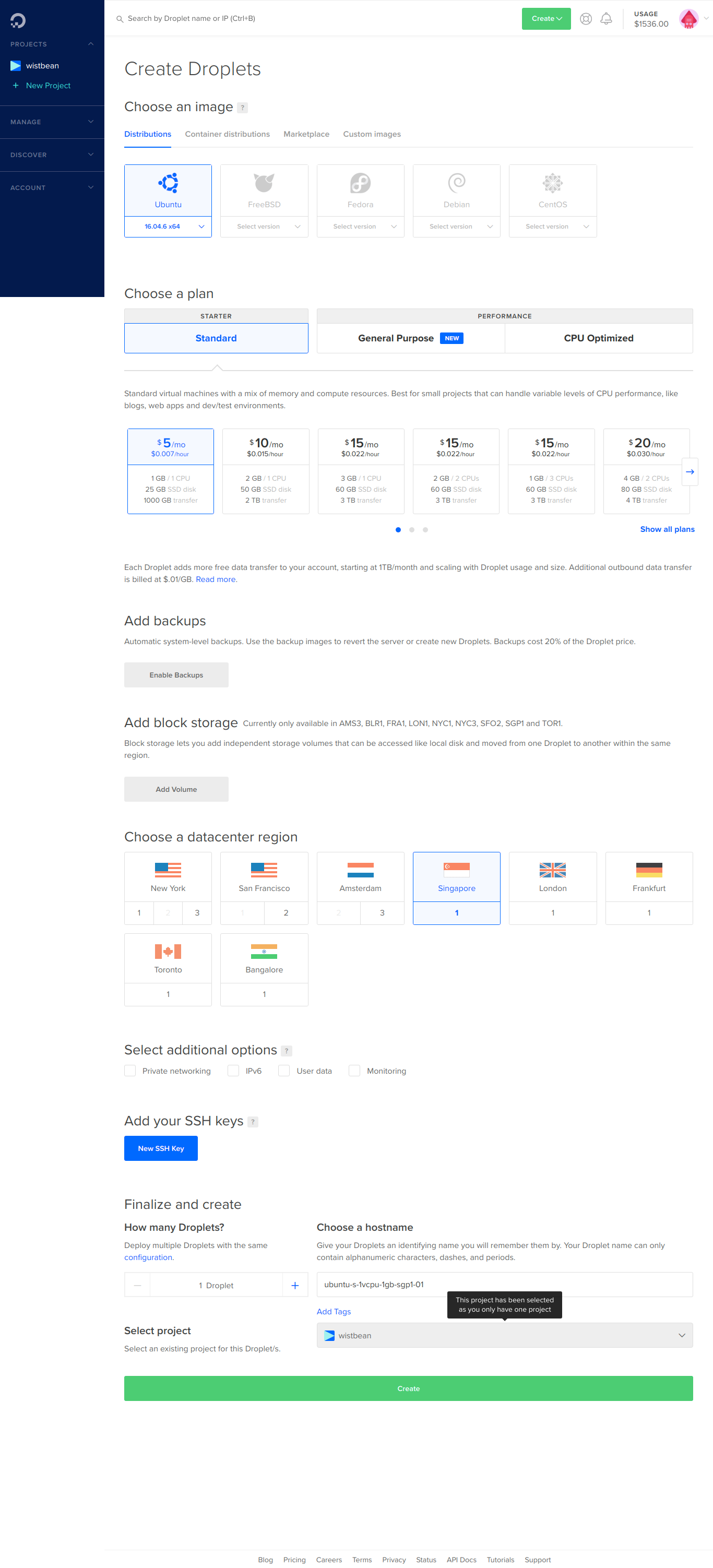
页面的 Location 就是选择服务器的地址,到时访问谷歌的时候会显示你当前访问的地址。好了,我们点击「Add to Cart」。
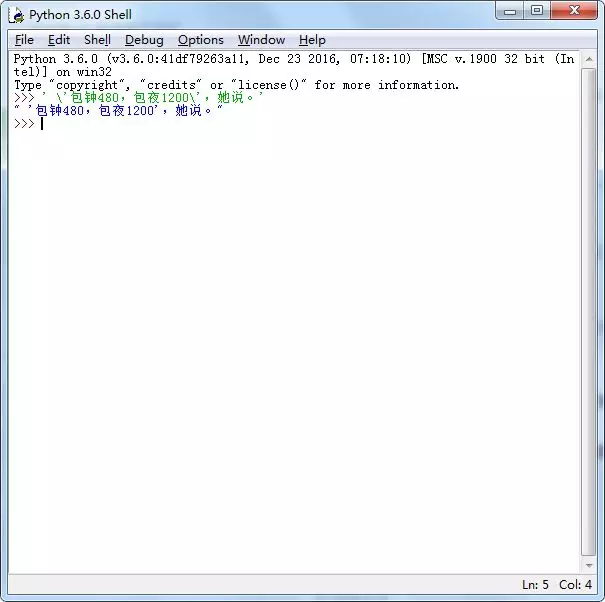
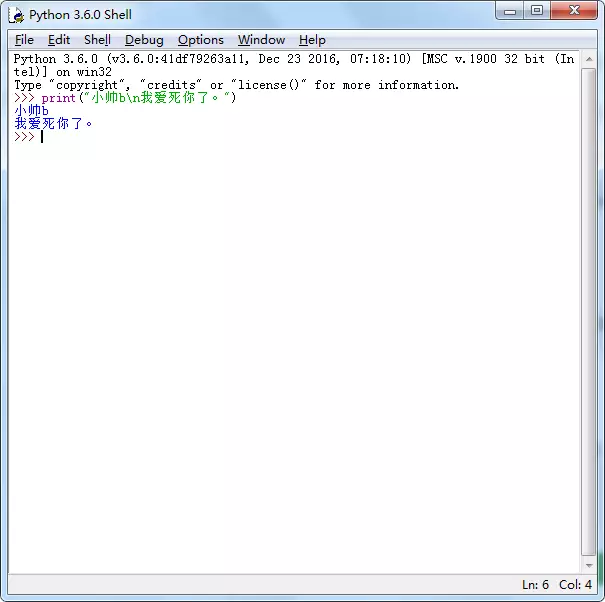
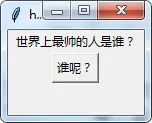
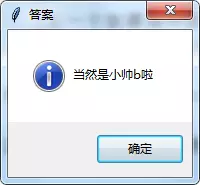
比较早关注我博客的朋友知道我这个名称,后来我弄了个 Python 公众号,起了个「小帅b」的昵称,喜欢的人喜欢至极,觉得好玩,讨厌的人恨之入骨,觉得不入流,觉得奇奇怪怪,特别是那个字母,对有些人来说是有恐惧症的,过于敏感。这也让我想不通为什么 b 站不叫 p 站,p 站不叫 b 站?可能是文化差异吧。
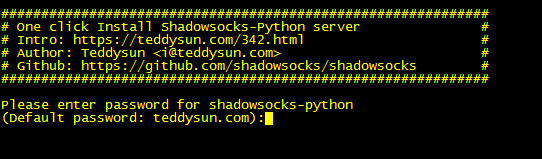
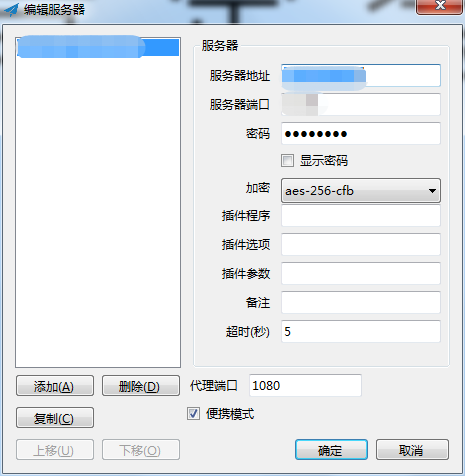
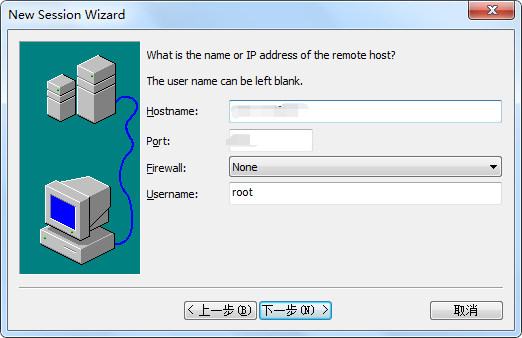
Please enter password for ShadowsocksR: (Default password: teddysun.com) : (在这里输入密码然后回车)
接着会提示你输入端口号:
1
Please enter a port for ShadowsocksR [1-65535] (Default port: 14593):(在这里输入端口然后回车)
接着会提示你输入加密方式:
1
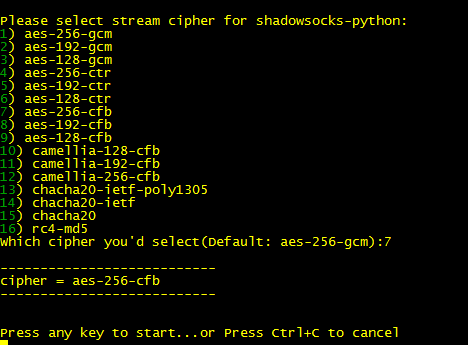
Please select stream cipher for ShadowsocksR:(这里输入 7 然后回车)
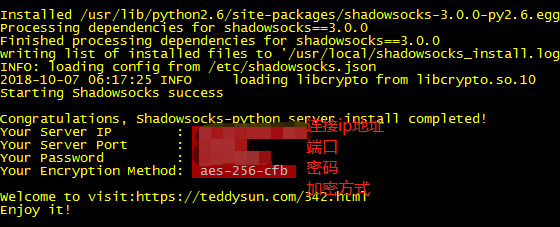
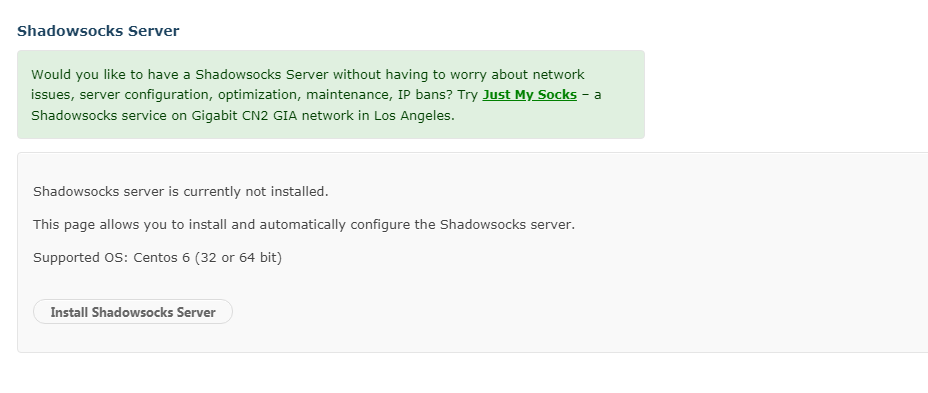
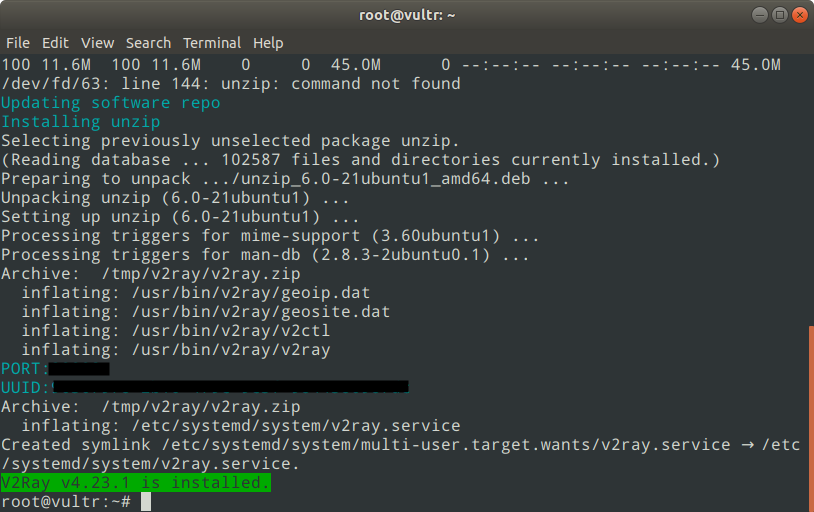
最后就会出现下面的内容,说明你已经安装ssr成功了:
1 2 3 4 5 6 7 8 9 10
Congratulations, ShadowsocksR server install completed! Your Server IP :服务器ip Your Server Port :端口 Your Password :密码 Your Protocol :协议 Your obfs :混淆 Your Encryption Method:your_encryption_method
Welcome to visit:https://shadowsocks.be/9.html Enjoy it!
如果这种对胃壁的习惯性挤压会刮掉其柔软的粘膜,使其暴露在腐蚀的胃液中,这可能会导致胃溃疡,Stewart wolf 和 Harold G. Wolff 博士有难得的机会看到这种情况发生。在他们的实验室工作的是一个瘦小而结实的男人,腹壁上有一个洞直接通向他的胃。他五十六岁,吞下了滚烫的蛤蜊浓汤。结果他的喉咙被烧伤,无法吞咽。外科医生不得不通过他的腹部进行永久性手术。然后他通过漏斗将食物直接放入胃中。他先咀嚼食物,当然是为了启动消化过程,所以他没有失去吃东西的乐趣。听上去很可怕,但他四十七年来一直这样走下去,这告诉我们一些人类有机体的适应能力。
很难意识到这些,你自己的习惯模式,因为它们与其说与你的思想有关,不如说与你的心脏、肠道和腺体的行为有关。当这种习惯模式受到挫折,或者它们所要求的行为无法继续时,你只会感到紧张。然后就产生了一种紧张感,一种缺乏活力的感觉。也许是一份失去的工作,或者是一个随风而去的农场。也许你已经从学校毕业,到了九月份,你会怀念过去的学校习惯和协会,也许你有一种被 AI 取代的贸易技能。
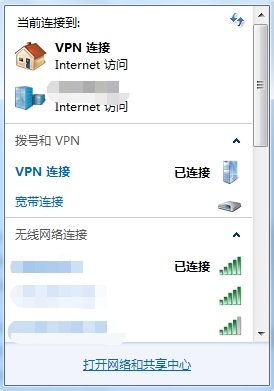
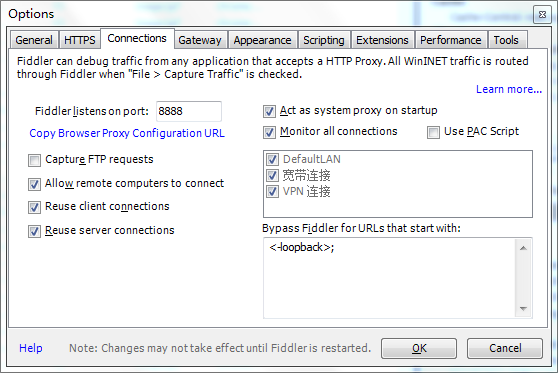
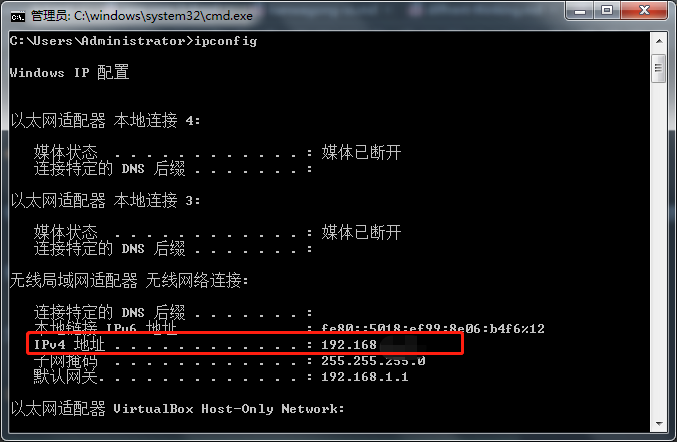
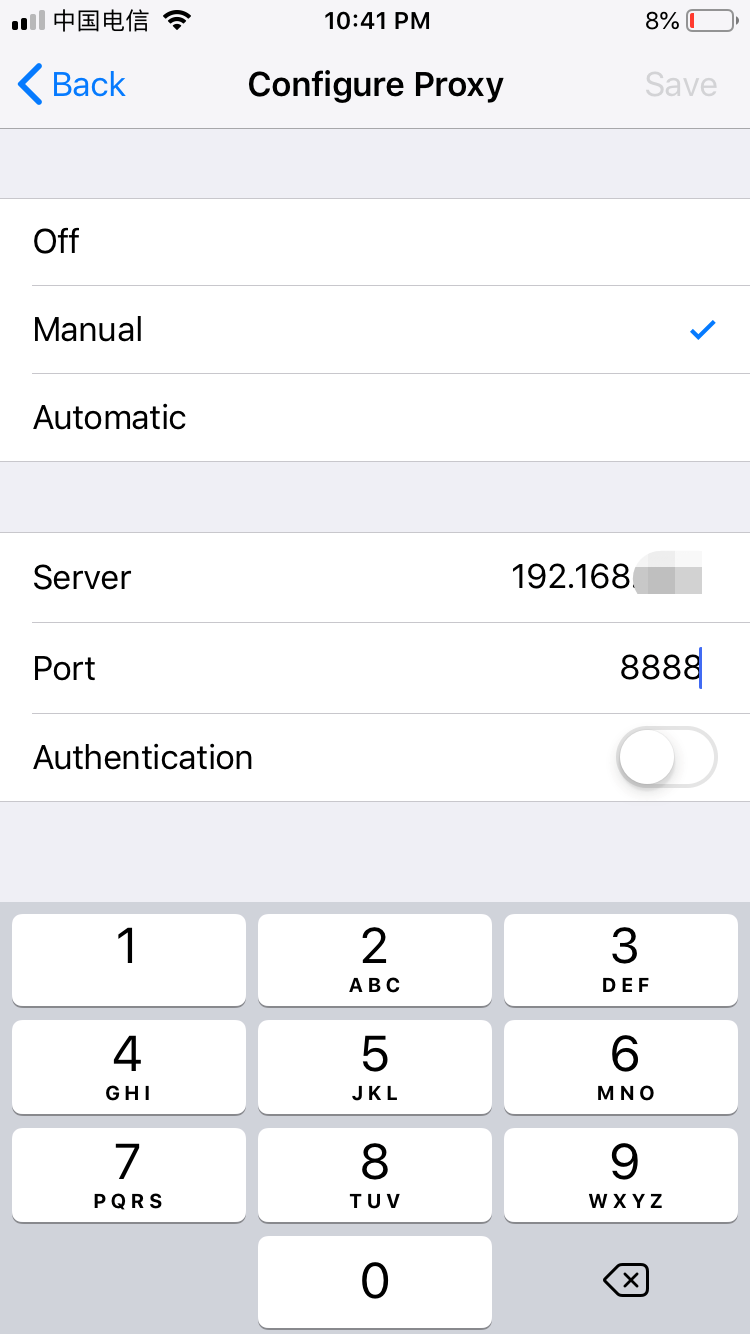
Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\RasMan\Parameters]"ProhibitIpSec"=dword:00000000[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\PolicyAgent]"AssumeUDPEncapsulationContextOnSendRule"=dword:00000002
另存为.reg格式的文件,然后双击。
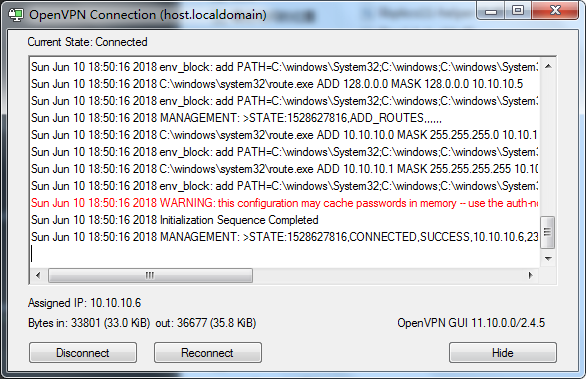
启动服务
将以下服务全部设置为自动启用,要不然会连接不成功:
IPsec Policy AgentRouting and Remote AccessRemote Access Auto Connection ManagerRemote Access Connection ManagerSecure Socket Tunneling Protocol Service
当你进到这个页面的时候呢,别急着点击「Add to Cart」添加到购物车,这里面暗藏着一个优惠码,很多人不知道,使用浏览器查看源代码, chrome浏览器的话按F12,然后搜索「code」,你会发现有一个 「Try this promo code: xxxx 」,这个xxxx就是优惠码,你把他复制下来,待会有用。
使用搬瓦工搭建VPN
页面的 Location 就是选择服务器的地址,到时访问谷歌的时候会显示你当前访问的地址。好了,我们点击「Add to Cart」。
当你进到这个页面的时候呢,别急着点击「Add to Cart」添加到购物车,这里面暗藏着一个优惠码,很多人不知道,使用浏览器查看源代码,chrome浏览器的话按F12,然后搜索「code」,你会发现有一个 「Try this promo code: xxxx 」,这个xxxx就是优惠码,你把他复制下来,待会有用。
使用搬瓦工优惠码
页面的 Location 就是选择服务器的地址,到时访问谷歌的时候会显示你当前访问的地址。好了,我们点击「Add to Cart」。
Please enter password for ShadowsocksR: (Default password: teddysun.com) : (在这里输入密码然后回车)
接着会提示你输入端口号:
1
Please enter a port for ShadowsocksR [1-65535] (Default port: 14593):(在这里输入端口然后回车)
接着会提示你输入加密方式:
1
Please select stream cipher for ShadowsocksR:(这里输入 7 然后回车)
最后就会出现下面的内容,说明你已经安装ssr成功了:
1 2 3 4 5 6 7 8 9 10
Congratulations, ShadowsocksR server install completed! Your Server IP :服务器ip Your Server Port :端口 Your Password :密码 Your Protocol :协议 Your obfs :混淆 Your Encryption Method:your_encryption_method
Welcome to visit:https://shadowsocks.be/9.html Enjoy it!
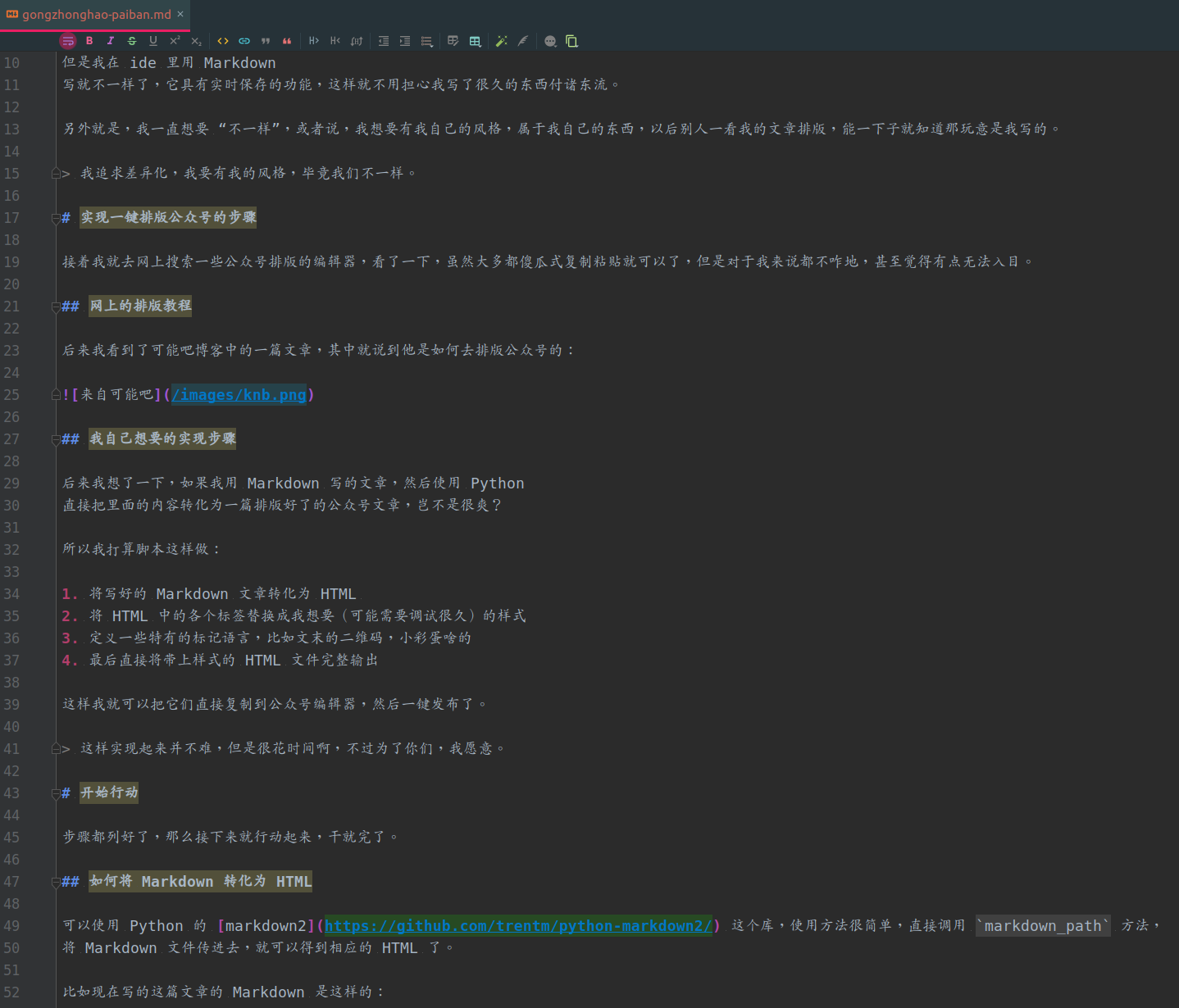
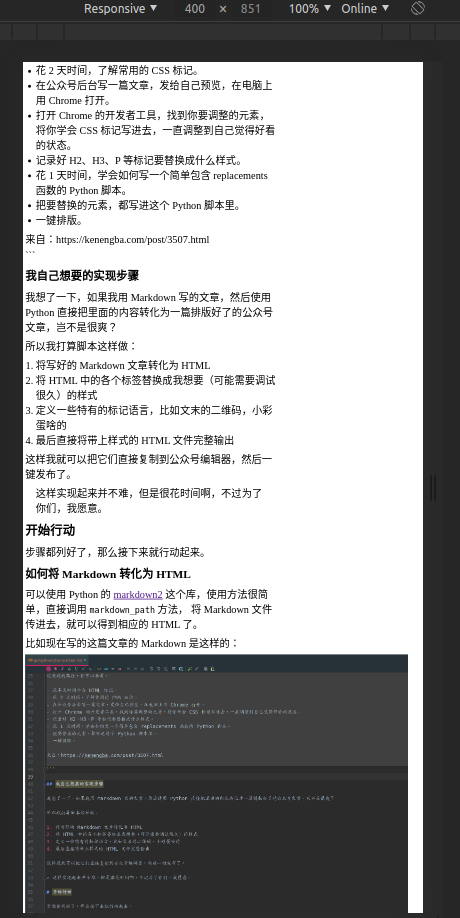
之前看一些 up 主分享的原创视频,短短几分钟看完乐呵完就完事了,但我现在愈加发现在这短短的视频背后他们付出了并不少,偶尔还会在观看的过程中琢磨一下他们是如何创作的。比如我之前都非常随意,视频封面随便截张图就整上去了,想着说想看我内容的人自然会看,现在发现并不是那么一回事,现在也会稍微琢磨下把封面捯饬捯饬。
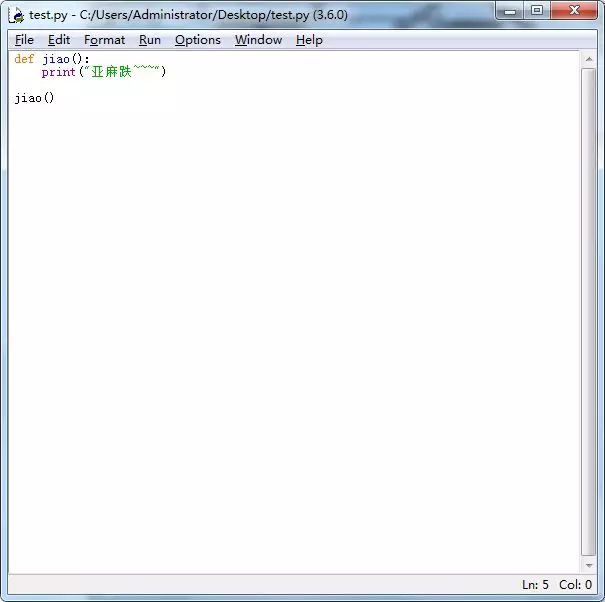
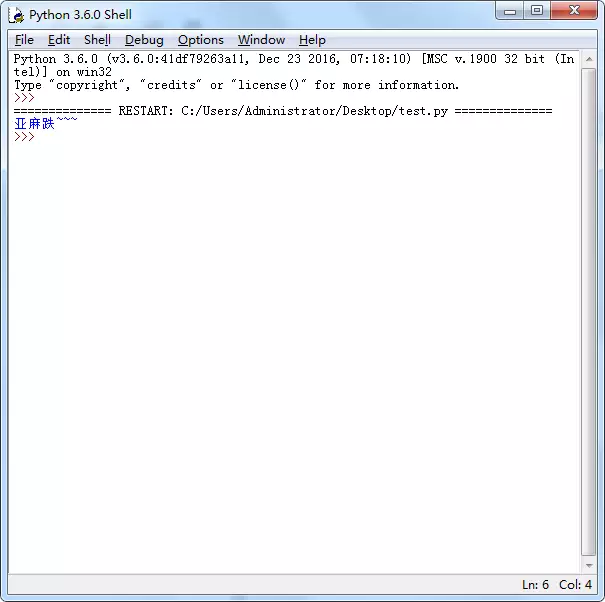
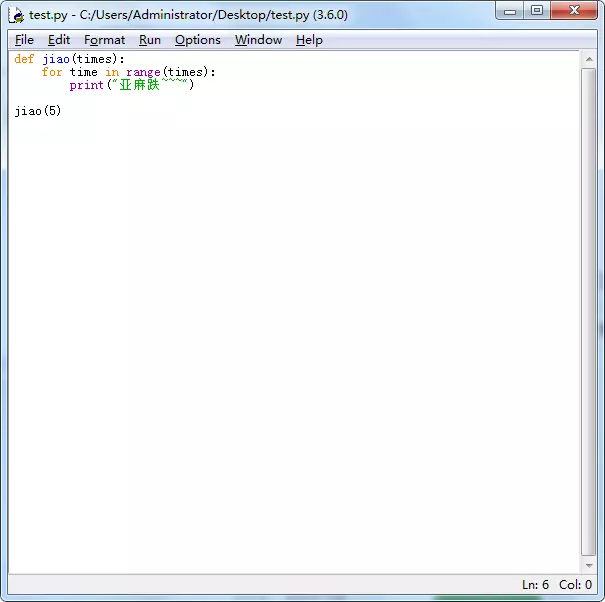
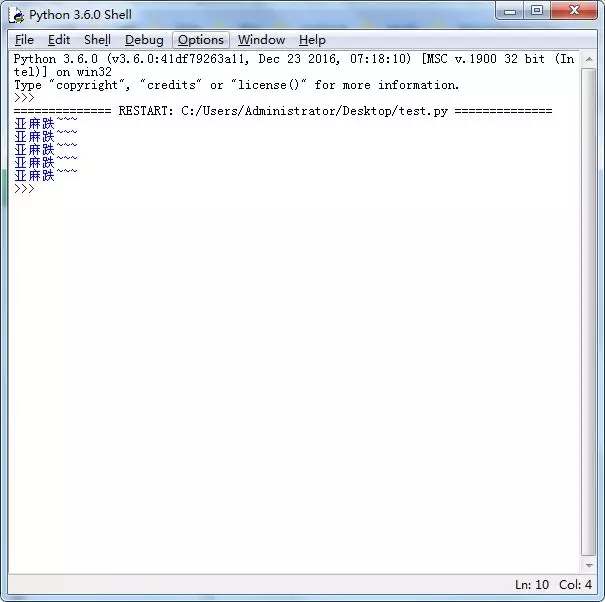
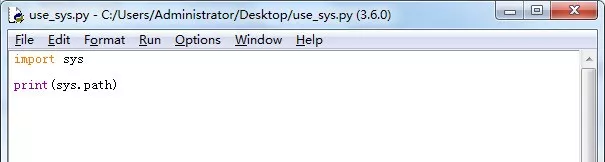
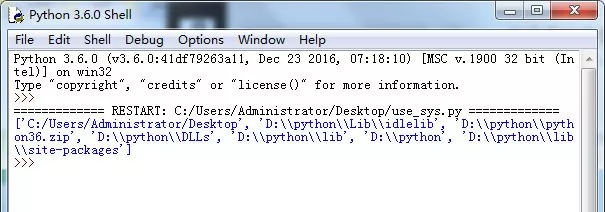
def myDoc(param1 ,param2): """ this is myDoc function :param param1: this is a first param :param param2: this is a second param :return: param1 + param2 """ print(param1 + param2) return param1 + param2
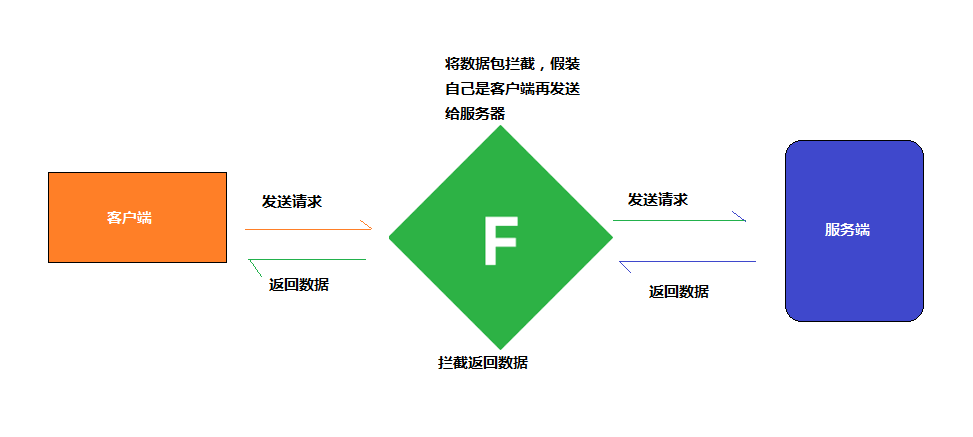
当然可以,那我先告诉你 IP 协议吧,假如我要发信息给你,我们都在互联网上,都有自己的 IP 地址和路由,那么当我发信息给你的时候呢,IP 协议就负责将数据进行传输,这些数据被分割成一小块一小块的,通过 IP 包给发送过去。因为们之间在互联网上是有很多链路的,所以路由就会将一小块一小块的数据包逐个进行转发,直到发送到你的IP地址。但是它不能够保证数据都能到达,也保证不了能够按顺序的到达。
]]>
<link rel="stylesheet" class="aplayer-secondary-style-marker" href="/assets/css/APlayer.min.css"><script src="/assets/js/APlayer.min.js" cla
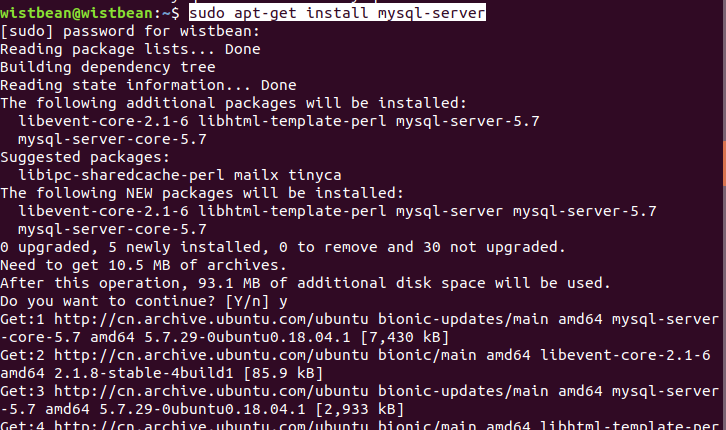
【解决】mysqlclient安装包错library not found for -lzstdhttps://wistbean.org/mysqlclient-install-error-lzstd.html2021-07-26T19:57:03.000Z2021-07-26T20:04:38.320Z
问题
在 mac 中安装 mysqlclient 报错如下:
1 2 3
ld: library not found for -lzstd clang: error: linker command failed with exit code 1 (use -v to see invocation) error: command 'xcrun' failed with exit status 1
我们在使用计算机的时候都知道,不同的系统,是没有办法兼容所有软件的,Windows 系统里的 exe 执行文件,就是无法在 Mac OS 中运行的, Linux 的操作方式,就是不适合在 Windows 里面操作的。在同一个系统中,我们只能安装对应的软件来使用,对吗?
人,也是一样的,长的好不好看,身材好不好,都是比较浅层的,它们虽然重要,但这仅仅是加分项,因为它们远没有这个人的「底层想法」重要,比如 TA 真正想要的是什么?TA 的能力是什么?
就像软件,你做得再好看再精美,如果没有操作系统支持,怎么运行得起来呢?
假如说,你为了培养一段长期关系,你发现对方的操作系统和你的不一样, TA 的是 Windows 系统,你的是 Linux 系统,你为了 TA 专门去开了个虚拟机,在里面安装了 Windows 系统跟 TA 交流,也许一开始你可以接受,但是久而久之你会发现,这是很容易「出轨」的,不兼容终究是不兼容,你就是不习惯甚至排斥用那种系统的软件,只好卸载掉,或者,你本就不想要一段长期关系,只是想要短暂的玩玩,那么开个虚拟机对你来说无所谓,反正,系统随便换嘛,你个跨平台的渣男。
在做产品之前,需要研究一下市场,知道什么东西可以做,什么东西不可以做。而趋势,就是判断的必要因素之一。就拿百度和微信来说,在互联网 PC 时代,百度的搜索以及互联网产品抓住了 PC 端的趋势,从而在 PC 端搜索一家独大。而到了移动互联网时代,微信崛起,各种移动端的服务层出不穷,微信成为了这个时代的不可撼动的地位。
我还记得之前刚开始学重装电脑系统的时候,把 U 盘在原有的系统上做成了启动盘,然后将要安装的新系统镜像文件放进去,接着重启电脑,把 F1 到 F12 都疯狂地按了个遍(那会我并不知道如何进入 BIOS 界面),试了很多次才进去,也花了挺多时间,才从 U 盘进入安装界面,然后开始重装系统…,等了挺长时间,系统提醒我安装成功,我有点激动,赶紧把 U 盘拔了,然后重启了电脑,果然,一个全新的操作系统展示在我的眼前,那一瞬间,突然感觉我的电脑焕然一新,虽然已经好多年过去了,但是那种感觉到现在还清楚的记得。
]]>
<link rel="stylesheet" class="aplayer-secondary-style-marker" href="/assets/css/APlayer.min.css"><script src="/assets/js/APlayer.min.js" cla
what the PUAhttps://wistbean.org/what-the-PUA.html2019-12-13T16:11:57.000Z2019-12-19T08:13:12.000Z
cd /usr/local/ wget https://wordpress.org/latest.tar.gz tar -zxvf latest.tar.gz
wordpress搭建教程
配置 wordpress
ok,现在环境都安装完毕了,接下来稍微做下配置就可以了。
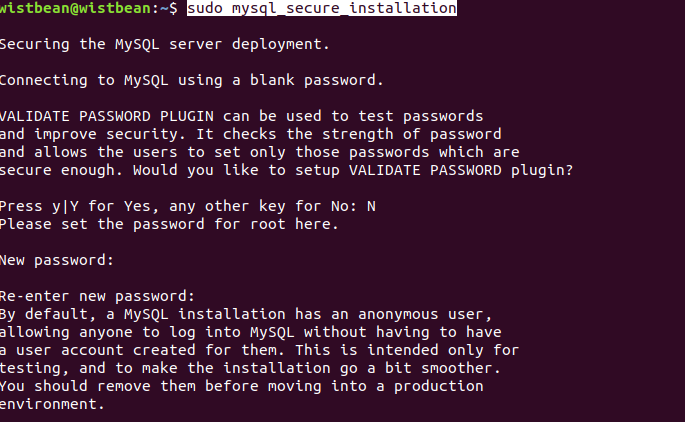
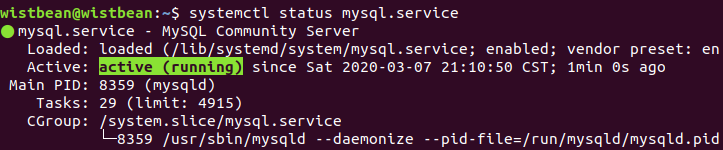
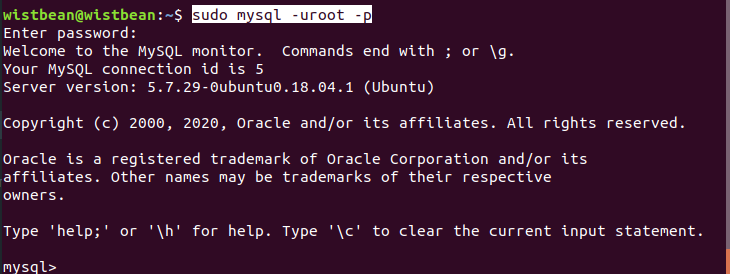
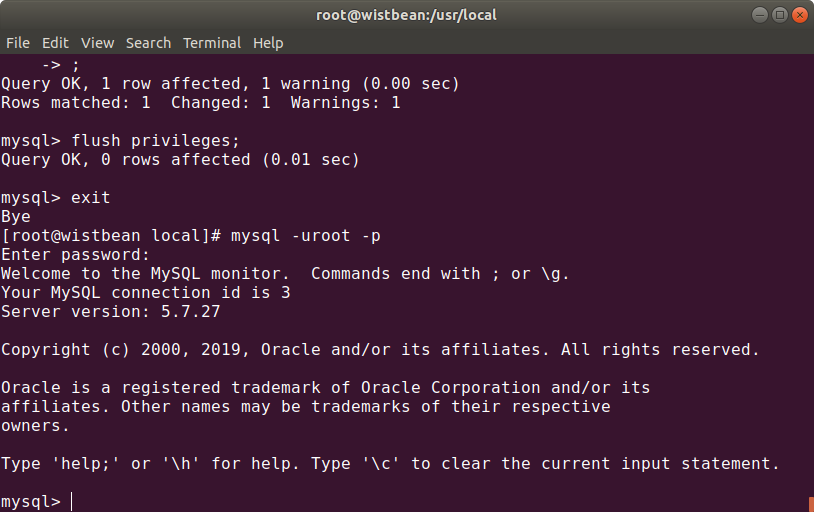
进入 mysql,设置下密码:
1
systemctl stop mysqld
1
mysqld --user=root --skip-grant-tables &
1
mysql -uroot
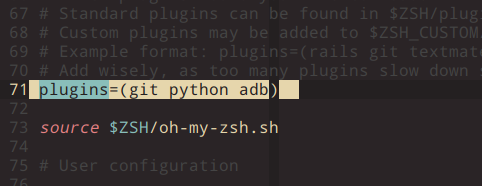
1 2
UPDATE mysql.user SET authentication_string=PASSWORD('设置你的密码') where USER='root'; GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' IDENTIFIED BY '你的密码' WITH GRANT OPTION;
刷新权限
1
flush privileges;
退出,重新登录:
1 2
exit mysql -uroot -p
wordpress搭建教程
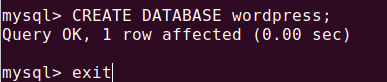
创建 wordpress 数据库
1
CREATE DATABASE wordpress;
wordpress搭建教程
配置 wordpress
退出mysql,然后进入 wordpress 目录:
1
cd /usr/local/wordpress/
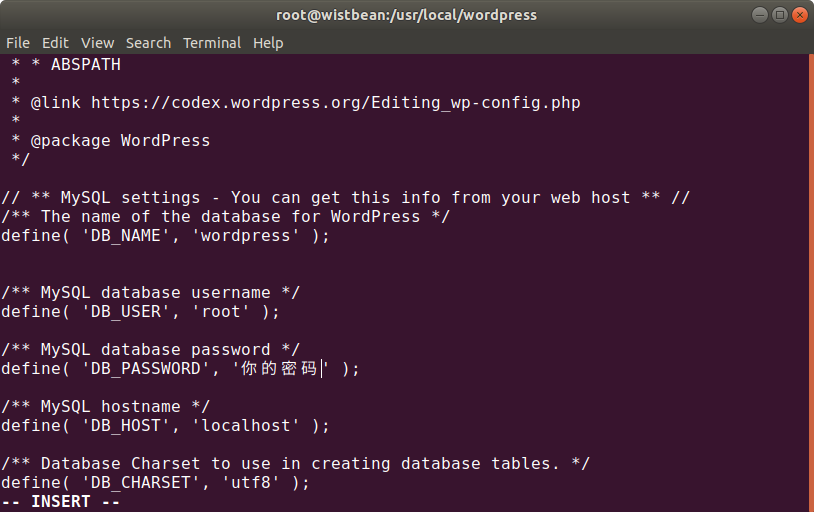
修改文件wp-config:
1
vi wp-config-sample.php
改下面几行,就是你刚刚创建的数据库名称和密码:
1 2 3 4 5 6 7 8 9 10 11
define( 'DB_NAME', 'wordpress' );
/** MySQL database username */ define( 'DB_USER', 'root' );
/** MySQL database password */ define( 'DB_PASSWORD', '你的密码' );
/** MySQL hostname */ define( 'DB_HOST', 'localhost' );
在做产品之前,需要研究一下市场,知道什么东西可以做,什么东西不可以做。而趋势,就是判断的必要因素之一。就拿百度和微信来说,在互联网 PC 时代,百度的搜索以及互联网产品抓住了 PC 端的趋势,从而在 PC 端搜索一家独大。而到了移动互联网时代,微信崛起,各种移动端的服务层出不穷,微信成为了这个时代的不可撼动的地位。再举一个例子,前不久 b 站的何同学做了一个关于 5G 的评测视频火了一把,有人开玩笑说,“他是得到 5G 红利的第一人”。你看,这就是趋势。
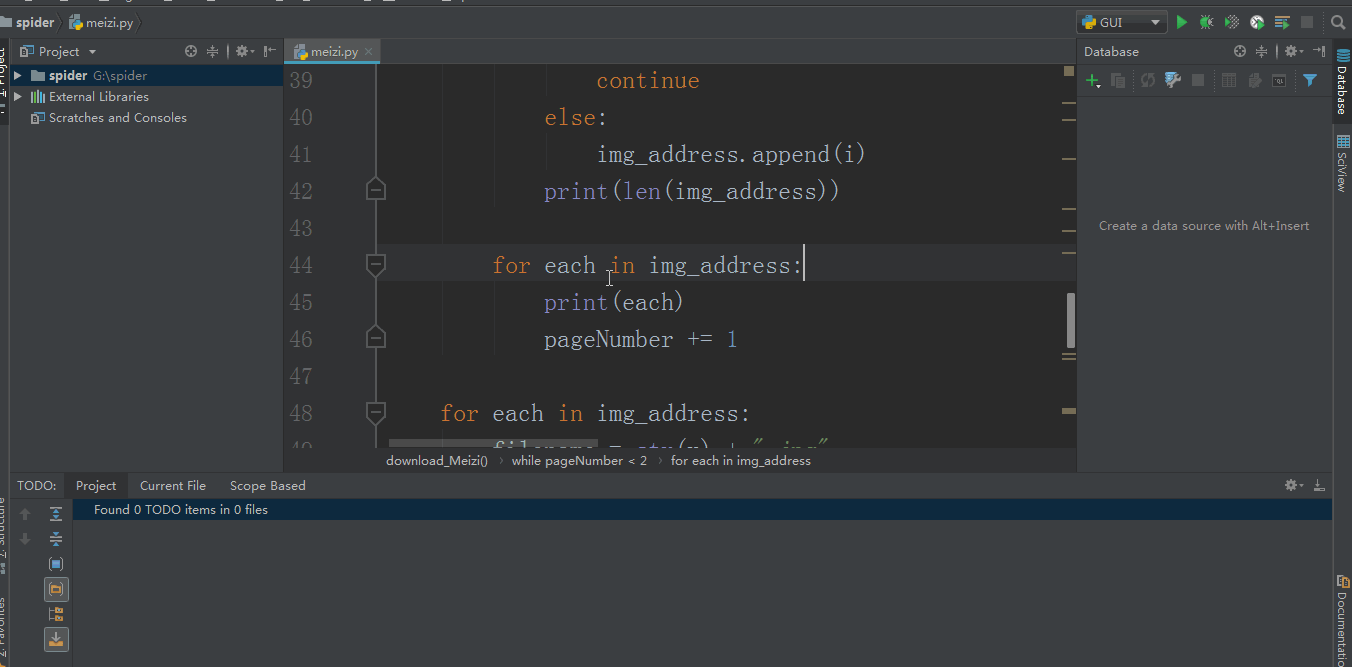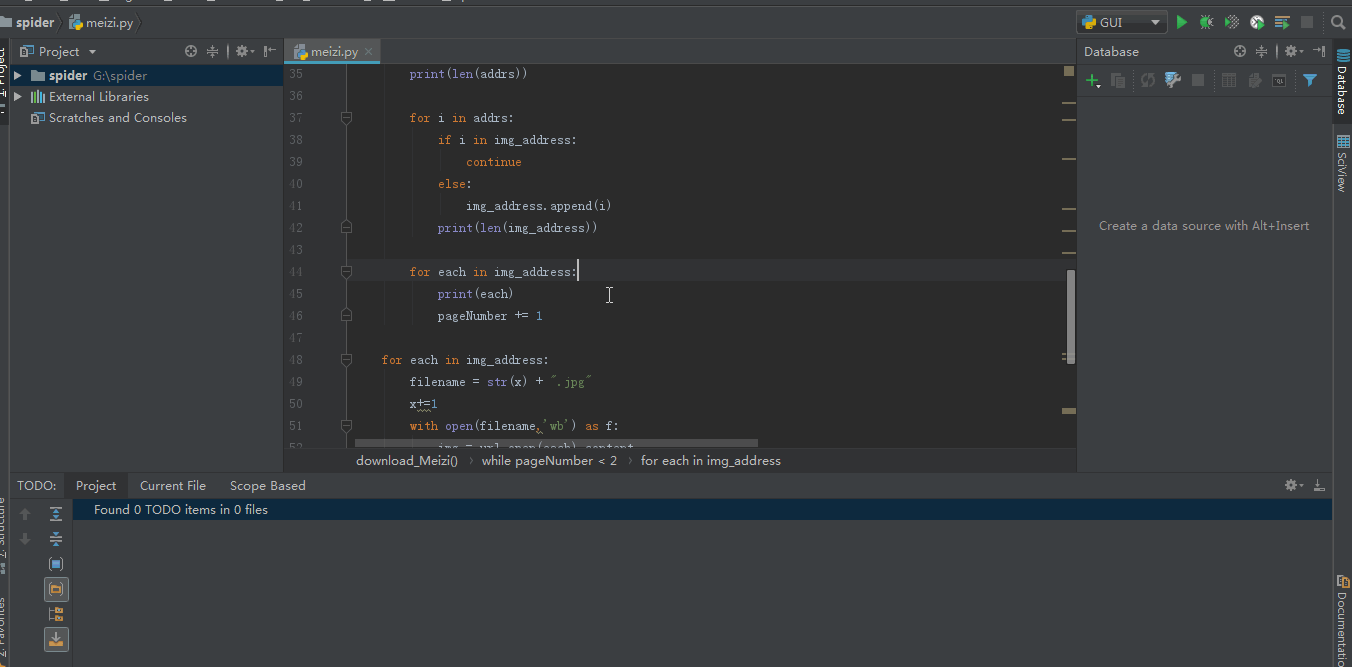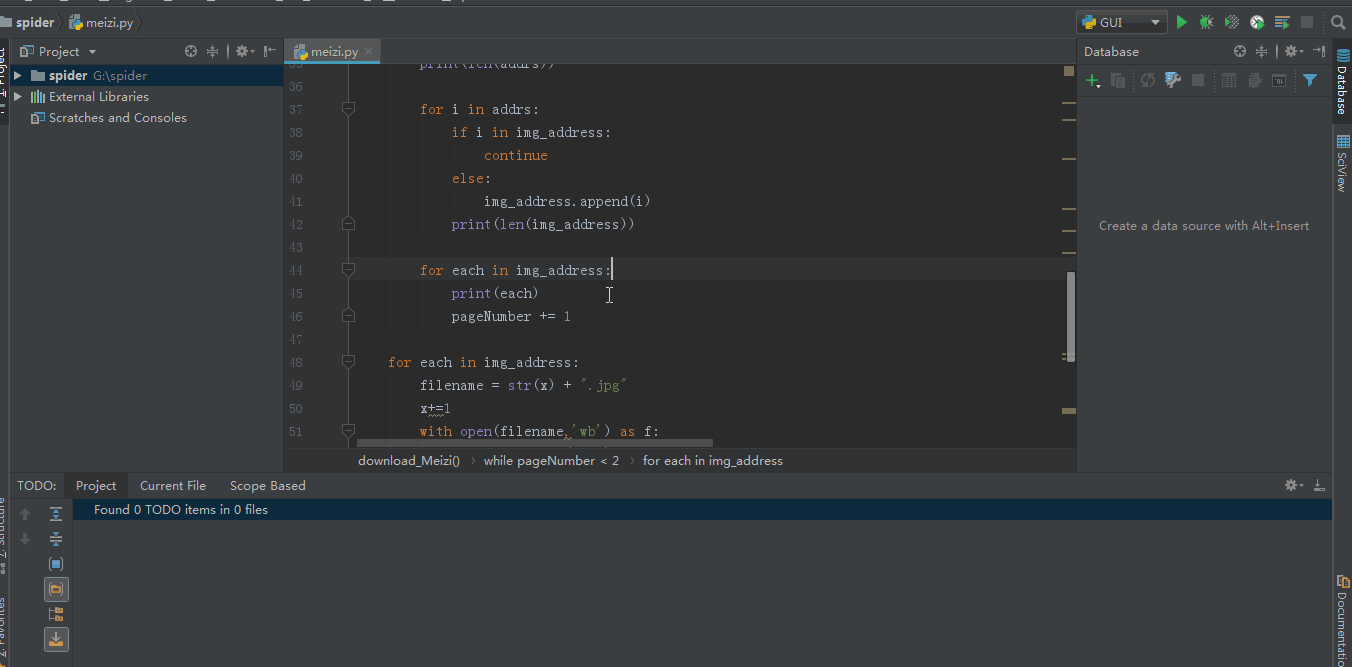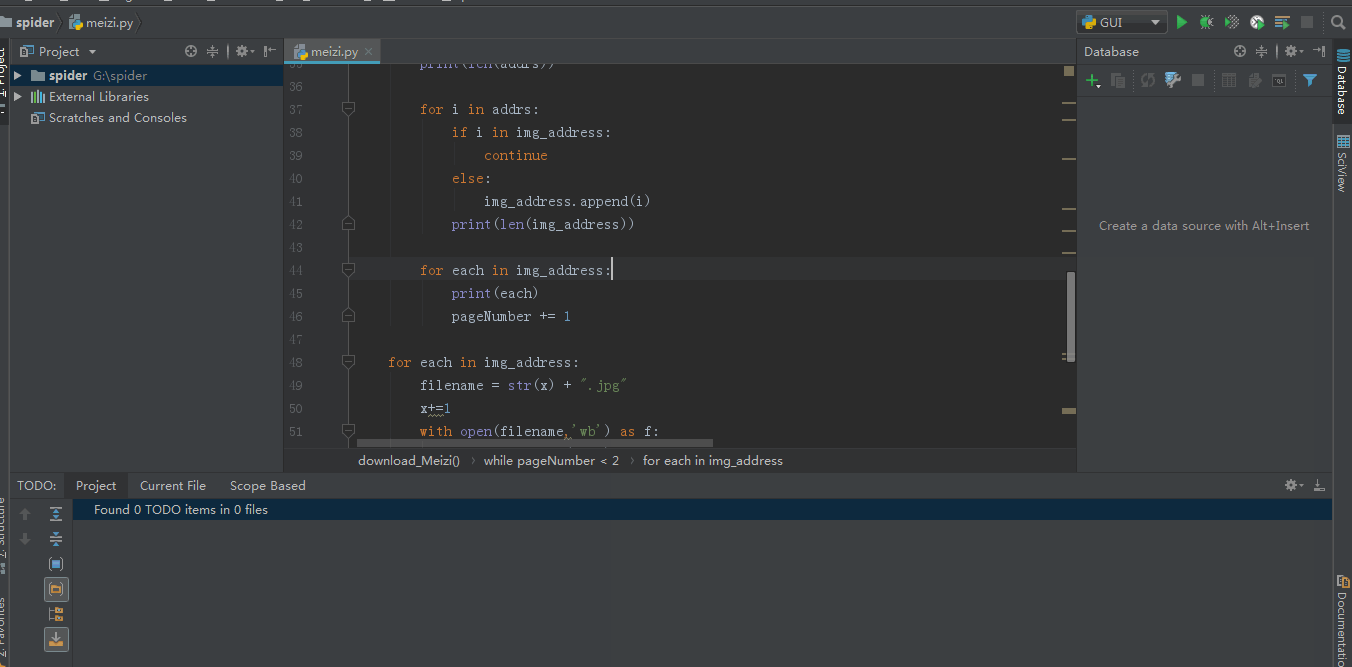
for img in img_list: image = img.get('data-original') title = img.get('title') # print(image) with open(path + title + os.path.splitext(image)[-1], 'wb') as f: img = requests.get(image).content f.write(img)
if next_page isnotNone:yield response.follow(next_page, callback=self.parse)
你也可以用 urljoin 的方式
# if next_page is not None:# next_page = response.urljoin(next_page)# yield scrapy.Request(next_page, callback=self.parse)
这样我们就可以获取到所有页面的数据了
接下来我们要把所有的数据保存到数据库
首先我们在 items.py 中定义一下我们要存储的字段
importscrapy classQiushibaikeItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field()author = scrapy.Field()content = scrapy.Field() _id = scrapy.Field()
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { 'qiushibaike.pipelines.QiushibaikePipeline': 300,}
这样才可以使用到pipelines
当然我们还可以在 settings.py 里面做更多的设置
比如设置请求头
# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.86 Chrome/73.0.3683.86 Safari/537.36'
这篇文章不适合急性子的人看,要不然会把手机砸了的!但是,如果你能看完,那么正则表达式对你来说,算个 p 的难度啊?
其实
正则表达式不仅仅适用于 python
很多编程语言
很多地方都会使用到正则
试想一下
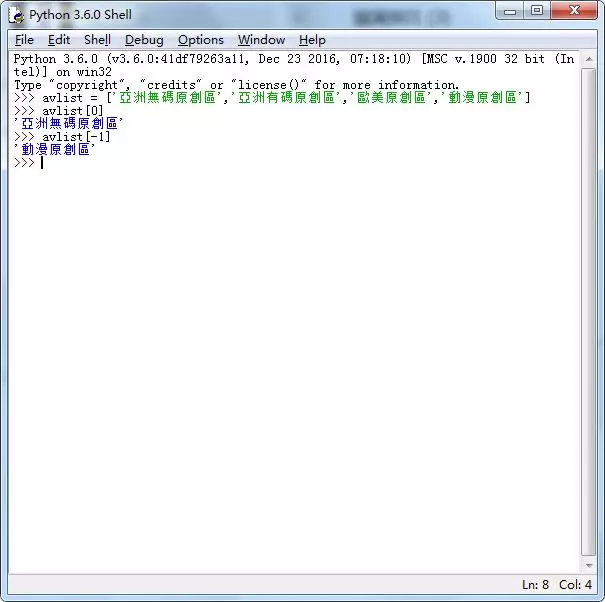
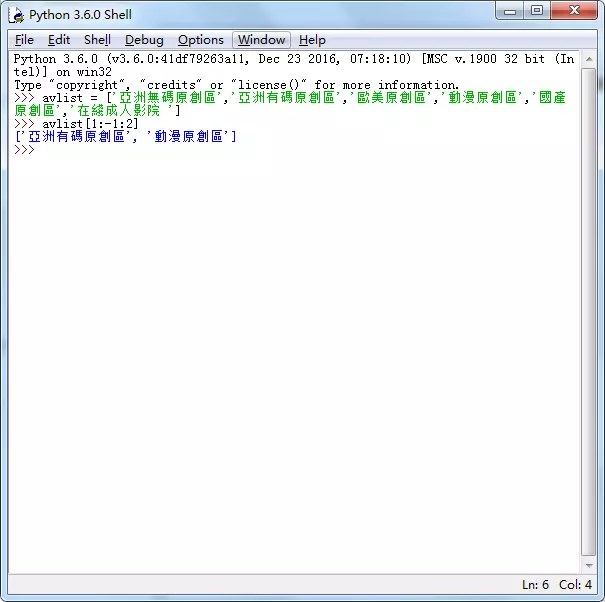
如何从下面这段字符串中快速检索所有的数字出来呢?
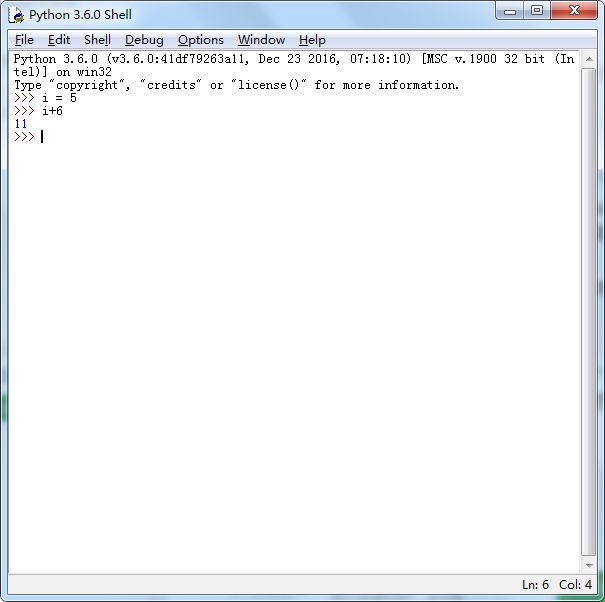
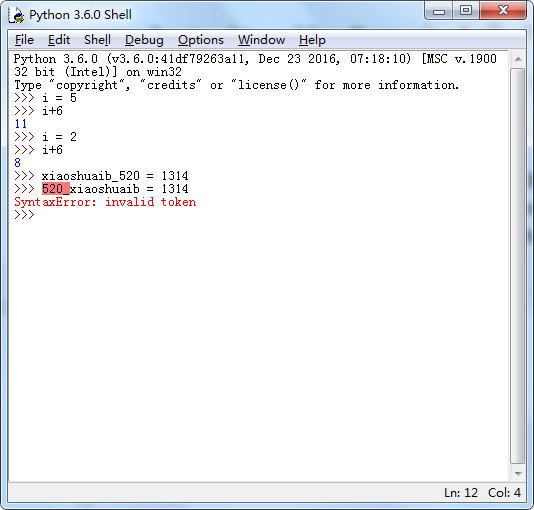
zui12shu234ai45der6en7sh88ixia7898os0huaib
简单来说
正则表达式就是定义一些特殊的符号
来匹配不同的字符
比如
\d
就可以代表
一个数字,等价于 0-9 的任意一个
那么你肯定想知道
其它的特殊符号表示的啥意思吧?
恩
就不告诉你
本篇完
再见
这是各种符号的解释
字符
描述
\
将下一个字符标记为一个特殊字符(File Format Escape,清单见本表)、或一个原义字符(Identity Escape,有^$()*+?.[\{|共计12个)、或一个向后引用(backreferences)、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
content = 'Xiaoshuaib has 100 bananas' res = re.match('^Xi.*(\d+)\s.*s$',content) print(res.group(1))
通过我们刚刚说的匹配符号
可以定义出相应的匹配规则
在这里我们将我们需要的目标内容用 () 括起来
此刻我们获得结果是
0
那么如果我们想要 100 这个数字呢?
可以这样
import re
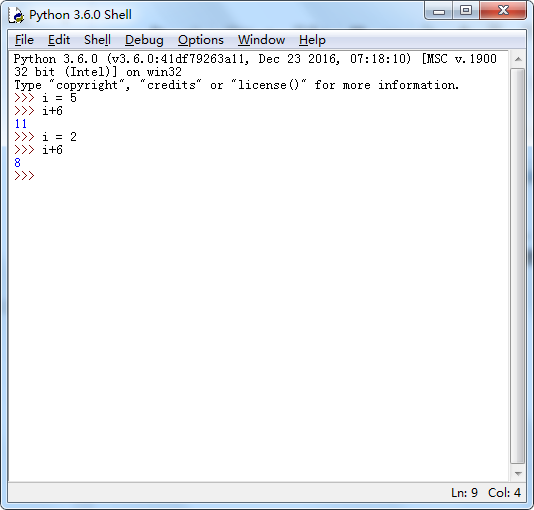
content = 'Xiaoshuaib has 100 bananas' res = re.match('^Xi.*?(\d+)\s.*s$',content) print(res.group(1))
看出区别了么
第二段代码我们多了一个 ?符号
在这里呢
涉及到两个概念
一个是
贪婪匹配
另一个是
非贪婪匹配
所谓贪婪匹配
就是我们的第一段代码
一个数一个数都要去匹配
而非贪婪呢
我们是直接把 100 给匹配出来了
刚刚我们用到的
.*?
是我们在匹配过程中最常使用到的
表示的就是匹配任意字符
但是
.*?的 . 代表所有的单个字符,除了 \n \r
如果我们的字符串有换行了
怎么办呢?
比如这样
content = """Xiaoshuaib has 100 bananas"""
那么我们就需要用到 re 的匹配模式了
说来也简单
直接用 re.S 就可以了
import re
content = """Xiaoshuaib has 100 bananas""" res = re.match('^Xi.*?(\d+)\s.*s$',content,re.S) print(res.group(1))
可能有些朋友会觉得
匹配一个东西还要写开头结尾
有点麻烦
那么就可以使用 re 的另一个方法了
re.search
它会直接去扫描字符串
然后把匹配成功的第一个结果的返回给你
import re
content = """Xiaoshuaib has 100 bananas""" res = re.search('Xi.*?(\d+)\s.*s',content,re.S) print(res.group(1))
这样子也是可以获取 100 的
但是如果我们的内容是这样的
content = """Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas;"""
想要获取所有的 100 呢?
这时候就要用到 re 的另一个方法了
re.findall
通过它我们就能轻松的获取所有匹配的内容了
import re
content = """Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas;""" res = re.findall('Xi.*?(\d+)\s.*?s;',content,re.S) print(res)
这里的结果是
['100', '100', '100', '100']
又有朋友觉得
如果我们想直接替换匹配的内容呢
就比如刚刚的字符串
可不可以把 100 直接替换成 250 呢?
那就要用到 re 的另一个方法了
re.sub
可以这样
import re
content = """Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas; Xiaoshuaib has 100 bananas;""" content = re.sub('\d+','250',content) print(content)
那么结果就变成了
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
250 个香蕉
吃....得完么??
再来说说 re 的另一个常用到的方法吧
re.compile
这个主要就是把我们的匹配符封装一下
import re
content = "Xiaoshuaib has 100 bananas" pattern = re.compile('Xi.*?(\d+)\s.*s',re.S) res = re.match(pattern,content)
total = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.last > button")))returnint(total.text)
获取到总页数之后
我们就开始循环
for i inrange(2,int(total+1)):next_page(i)
如何获取下一页呢
当然是模拟点击「下一页按钮」的操作
我们获取「下一页按钮」的元素
然后点击
点击之后判断一下是否在我们当前的页数
然后获取数据
print('获取下一页数据')next_btn = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.next > button')))next_btn.click()WAIT.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#server-search-app > div.contain > div.body-contain > div > div.page-wrap > div > ul > li.page-item.active > button'),str(page_num)))get_source()
defdownload_all_images(list_page_urls):# 获取每一个详情妹纸 works = len(list_page_urls)with concurrent.futures.ThreadPoolExecutor(works) as exector:for url in list_page_urls: exector.submit(download,url)
from multiprocessing import Process deff(name): print('hello', name) if __name__ == '__main__': p = Process(target=f, args=('xiaoshuaib',)) p.start() p.join()
还可以使用进程池的方式
from multiprocessing import Pool deff(x):return x*x if __name__ == '__main__':with Pool(5) as p: print(p.map(f, [1, 2, 3]))
xiaoshuaib@xiaoshuaib:~$ javacUsage: javac <options> <source files>where possible options include: -g Generate all debugging info -g:none Generate no debugging info -g:{lines,vars,source} Generate only some debugging info -nowarn Generate no warnings -verbose Output messages about what the compiler is doing -deprecation Output source locations where deprecated APIs are used -classpath <path> Specify where to find user classfilesandannotationprocessors -cp <path> Specify where to find user classfilesandannotationprocessors -sourcepath <path> Specify where to find input source files -bootclasspath <path> Override location of bootstrap classfiles -extdirs <dirs> Override location of installed extensions -endorseddirs <dirs> Override location of endorsed standards path -proc:{none,only} Control whether annotation processing and/or compilation is done....
import numpy as npimport .pyplot as plt x = np.linspace(-np.pi, np.pi, 256) cos = np.cos(x)sin = np.sin(x) plt.plot(x, cos, '--', linewidth=2)plt.plot(x, sin) plt.show()
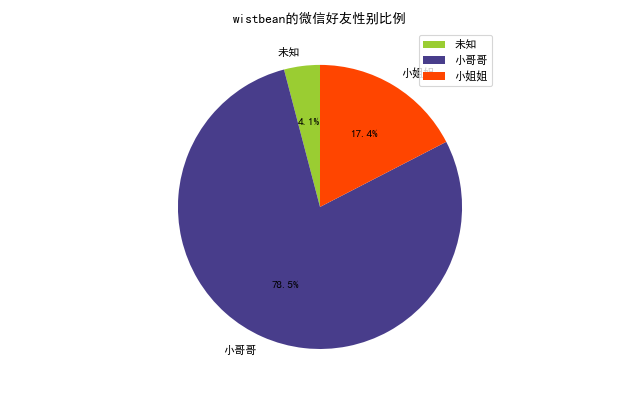
画个饼图
# Pie chart, where the slices will be ordered and plotted counter-clockwise:labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'sizes = [15, 30, 45, 10]explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs') fig1, ax1 = plt.subplots()ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True, startangle=90)ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle. plt.show()
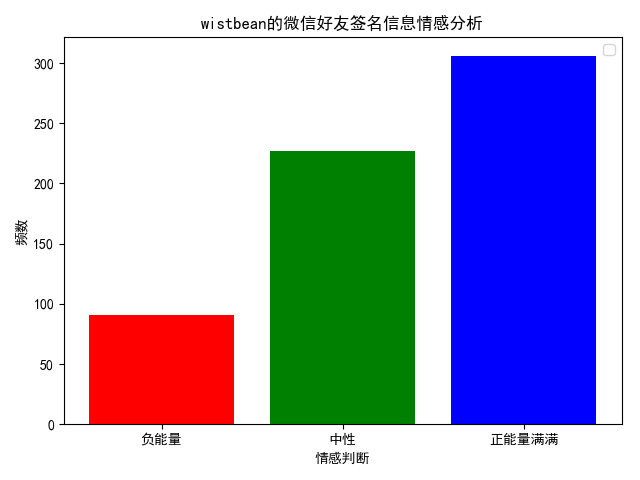
画画直方图
import numpy as npimport matplotlib.pyplot as plt np.random.seed(0) mu = 200sigma = 25x = np.random.normal(mu, sigma, size=100) fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(8, 4)) ax0.hist(x, 20, normed=1, histtype='stepfilled', facecolor='g', alpha=0.75)ax0.set_title('stepfilled') # Create a histogram by providing the bin edges (unequally spaced).bins = [100, 150, 180, 195, 205, 220, 250, 300]ax1.hist(x, bins, normed=1, histtype='bar', rwidth=0.8)ax1.set_title('unequal bins') fig.tight_layout()plt.show()
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snssns.set(style="darkgrid") tips = sns.load_dataset("tips")sns.relplot(x="total_bill", y="tip", data=tips);plt.show()
defpie_base() -> Pie: c = ( Pie() .add("", [list(z) for z in zip(Faker.choose(), Faker.values())]) .set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例")) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) )return c # 需要安装 snapshot_seleniummake_snapshot(driver, pie_base().render(), "pie.png")
List<Res_Categories.CategoriesBean> categories = new ArrayList<>();
for (int i = 0; i < productCategories.size(); i++) { Res_Categories.CategoriesBean categoriesBean = new Res_Categories.CategoriesBean(); categoriesBean.setCat_id(productCategories.get(i).getId()+""); categoriesBean.setName(productCategories.get(i).getName());
有很多网站的站长都在做 SEO ,也就是搜索引擎优化,为的就是能够将自己的网站能够被更容易被搜索得到。
可是,有些网站的站长,是不希望他们的网站被搜索引擎搜索得到的,甚至不希望被别人知道具体的服务器地址。也有些用户,他们不希望暴露自己的 IP 地址(尽管有些人挂代理,但是长时间使用同一个也会很容易被发现的),他们不希望被知道自己的访问记录,不希望被发现自己在网络上做的什么勾当。总而言之,他们都希望匿名,安全,不被泄露隐私。
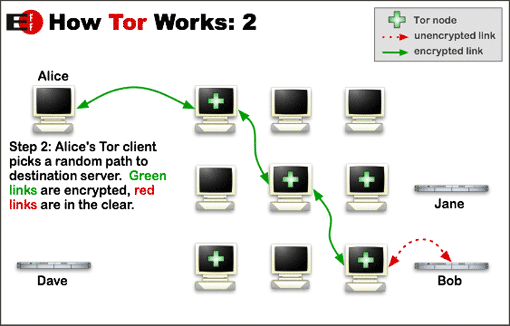
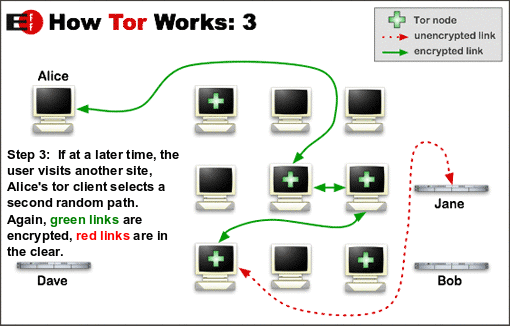
那么这个时候,暗网就正合他们之意。
暗网提供了匿名的网络,在这里,我们不用担心自己的隐私安全问题,因为我们每个人都可以成为每一个人的代理,并且层层加密,这样我们就可以做到真正隐藏自己的真实 IP 地址。
洋葱 Tor 浏览器
Tor 是一个分布式的匿名网络,当你通过 Tor 进入网络的时候,它首先会去找到那些分布在 Tor 上的节点。
return io; }, createUploadForm: function(id, fileElementId) { //create form var formId = 'jUploadForm' + id; var fileId = 'jUploadFile' + id; var form = jQuery('<form action="" method="POST" name="' + formId + '" id="' + formId + '" enctype="multipart/form-data"></form>'); var oldElement = jQuery('#' + fileElementId); var newElement = jQuery(oldElement).clone(); jQuery(oldElement).attr('id', fileId); jQuery(oldElement).before(newElement); jQuery(oldElement).appendTo(form); //set attributes jQuery(form).css('position', 'absolute'); jQuery(form).css('top', '-1200px'); jQuery(form).css('left', '-1200px'); jQuery(form).appendTo('body'); return form; },
ajaxFileUpload: function(s) { // TODO introduce global settings, allowing the client to modify them for all requests, not only timeout s = jQuery.extend({}, jQuery.ajaxSettings, s); var id = s.fileElementId; var form = jQuery.createUploadForm(id, s.fileElementId); var io = jQuery.createUploadIframe(id, s.secureuri); var frameId = 'jUploadFrame' + id; var formId = 'jUploadForm' + id;
if( s.global && ! jQuery.active++ ) { // Watch for a new set of requests jQuery.event.trigger( "ajaxStart" ); } var requestDone = false; // Create the request object var xml = {}; if( s.global ) { jQuery.event.trigger("ajaxSend", [xml, s]); }
var uploadCallback = function(isTimeout) { // Wait for a response to come back var io = document.getElementById(frameId); try { if(io.contentWindow) { xml.responseText = io.contentWindow.document.body?io.contentWindow.document.body.innerHTML:null; xml.responseXML = io.contentWindow.document.XMLDocument?io.contentWindow.document.XMLDocument:io.contentWindow.document;
}elseif(io.contentDocument) { xml.responseText = io.contentDocument.document.body?io.contentDocument.document.body.innerHTML:null; xml.responseXML = io.contentDocument.document.XMLDocument?io.contentDocument.document.XMLDocument:io.contentDocument.document; } }catch(e) { jQuery.handleError(s, xml, null, e); } if( xml || isTimeout == "timeout") { requestDone = true; var status; try { status = isTimeout != "timeout" ? "success" : "error"; // Make sure that the request was successful or notmodified if( status != "error" ) { // process the data (runs the xml through httpData regardless of callback) var data = jQuery.uploadHttpData( xml, s.dataType ); if( s.success ) { // ifa local callback was specified, fire it and pass it the data s.success( data, status ); }; if( s.global ) { // Fire the global callback jQuery.event.trigger( "ajaxSuccess", [xml, s] ); }; } else { jQuery.handleError(s, xml, status); }
} catch(e) { status = "error"; jQuery.handleError(s, xml, status, e); }; if( s.global ) { // The request was completed jQuery.event.trigger( "ajaxComplete", [xml, s] ); };
// Handle the global AJAX counter if(s.global && ! --jQuery.active) { jQuery.event.trigger("ajaxStop"); }; if(s.complete) { s.complete(xml, status); } ;
uploadHttpData: function( r, type ) { var data = !type; data = type == "xml" || data ? r.responseXML : r.responseText; // ifthe type is "script", eval it in global context if( type == "script" ) { jQuery.globalEval( data ); }
// Get the JavaScript object, ifJSON is used. if( type == "json" ) { eval( "data = " + data ); }
// evaluate scripts within html if( type == "html" ) { jQuery("<div>").html(data).evalScripts(); }
return data; }, handleError: function( s, xhr, status, e ) { // If a local callback was specified, fire it if ( s.error ) { s.error.call( s.context || s, xhr, status, e ); }
// Fire the global callback if ( s.global ) { (s.context ? jQuery(s.context) : jQuery.event).trigger( "ajaxError", [xhr, s, e] ); } } });
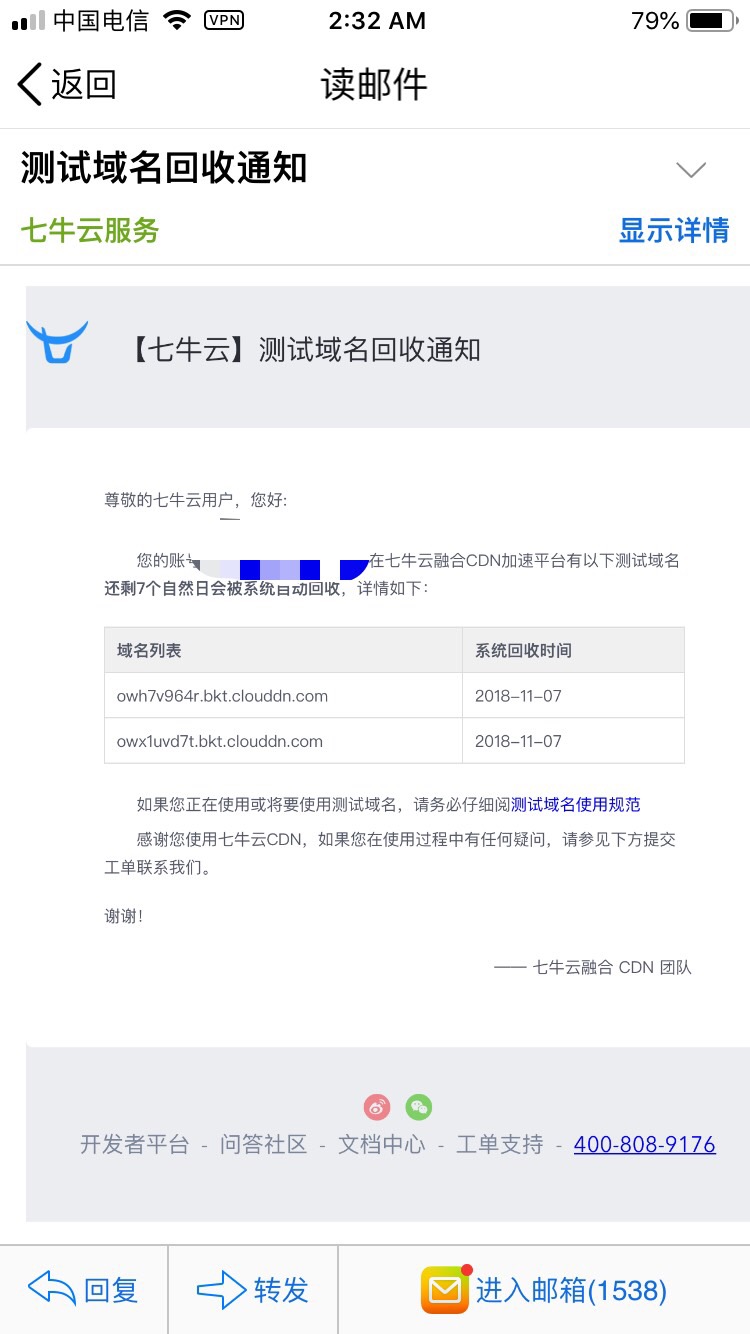
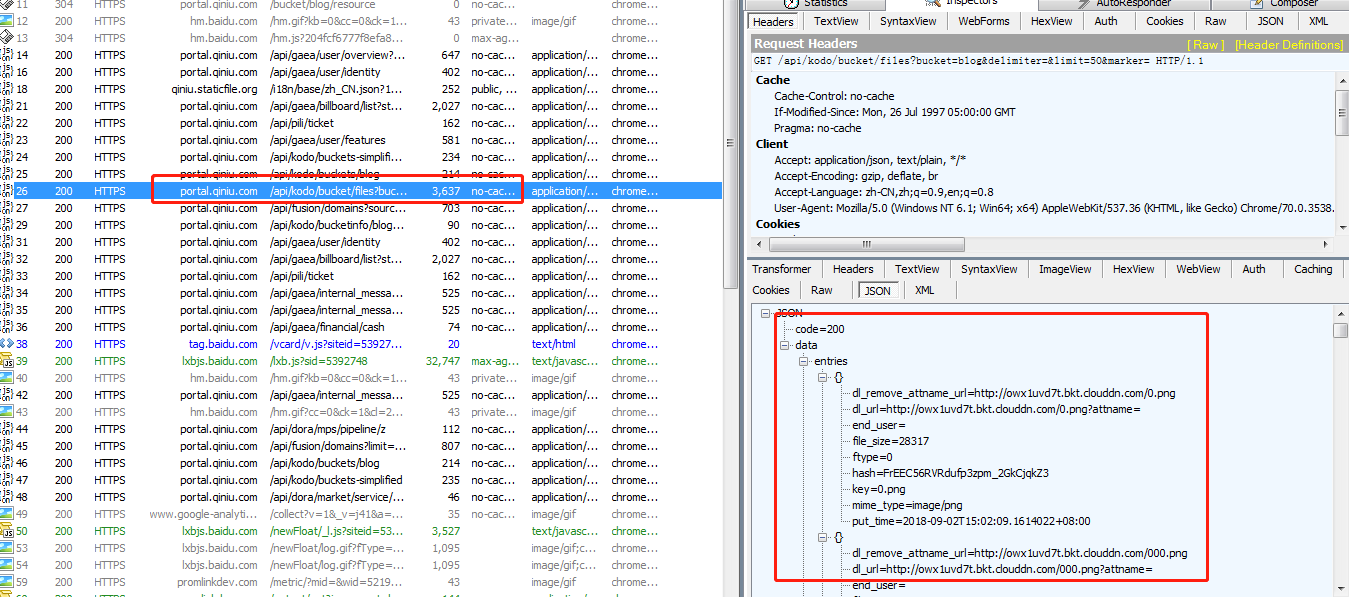
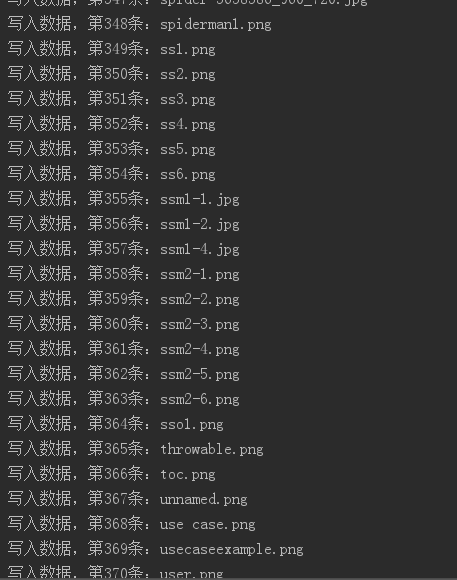
for i in range(0,len(jsondata['data']['entries'])): fileurl = jsondata['data']['entries'][i]['dl_remove_attname_url'] filename = jsondata['data']['entries'][i]['key'] with open(filename, 'wb') as f: img = url_open(fileurl).content f.write(img) sum += 1 print("写入数据,第"+str(sum)+"条:" + filename)
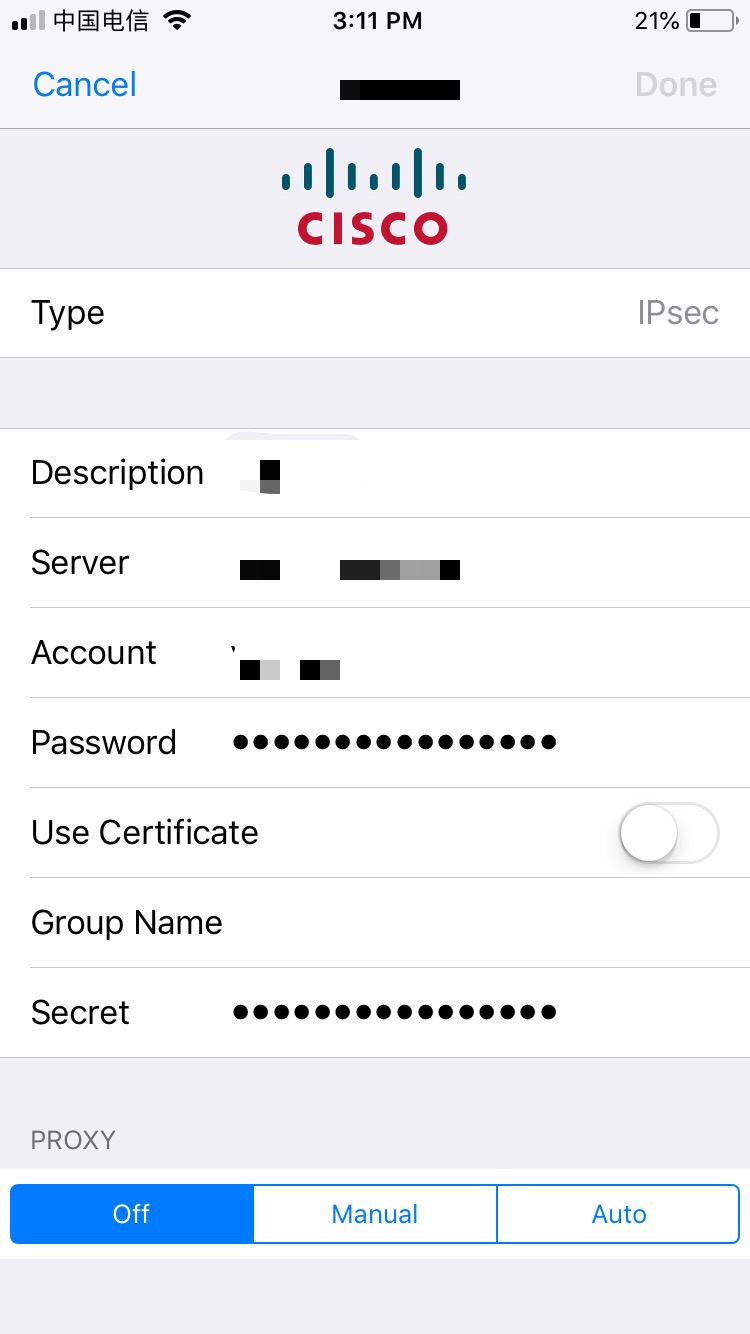
Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\RasMan\Parameters]"ProhibitIpSec"=dword:00000000[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\PolicyAgent]"AssumeUDPEncapsulationContextOnSendRule"=dword:00000002
另存为.reg格式的文件,然后双击。
启动服务
将以下服务全部设置为自动启用,要不然会连接不成功:
IPsec Policy AgentRouting and Remote AccessRemote Access Auto Connection ManagerRemote Access Connection ManagerSecure Socket Tunneling Protocol Service
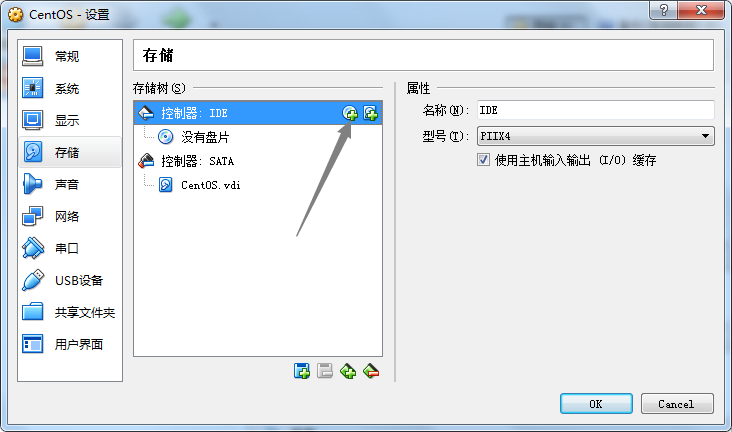
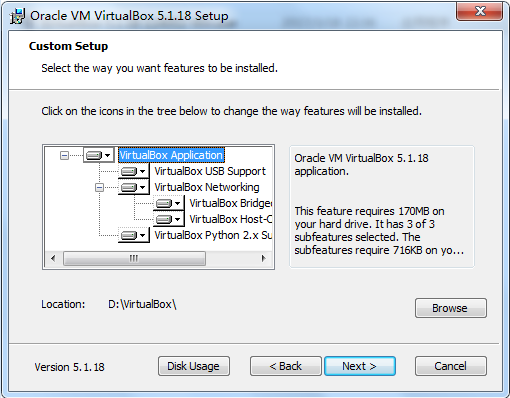
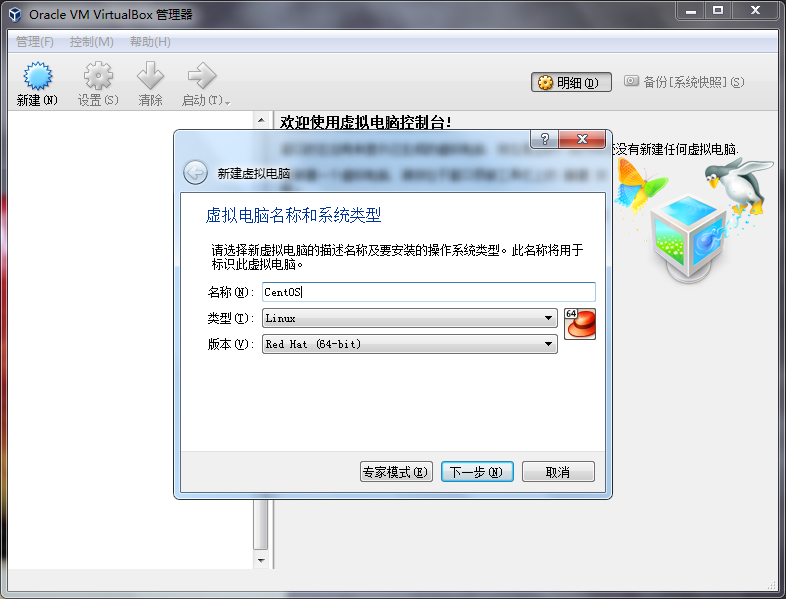
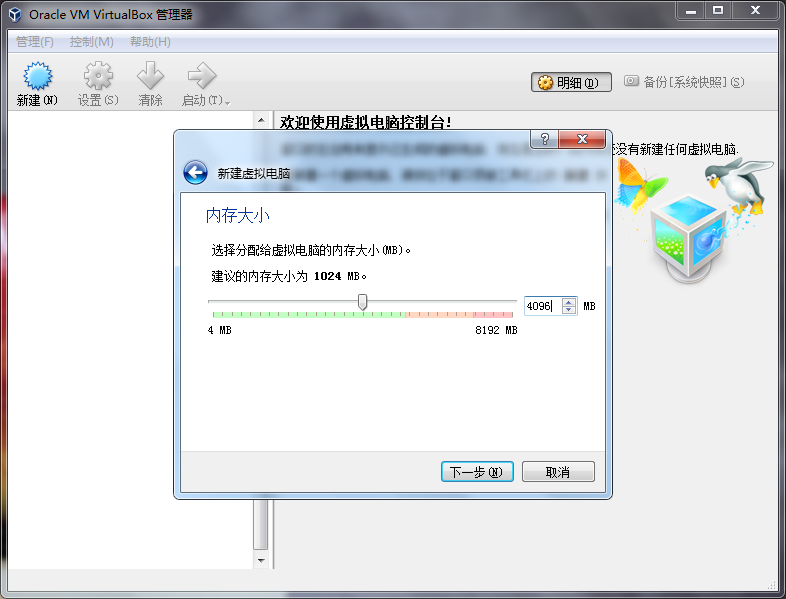
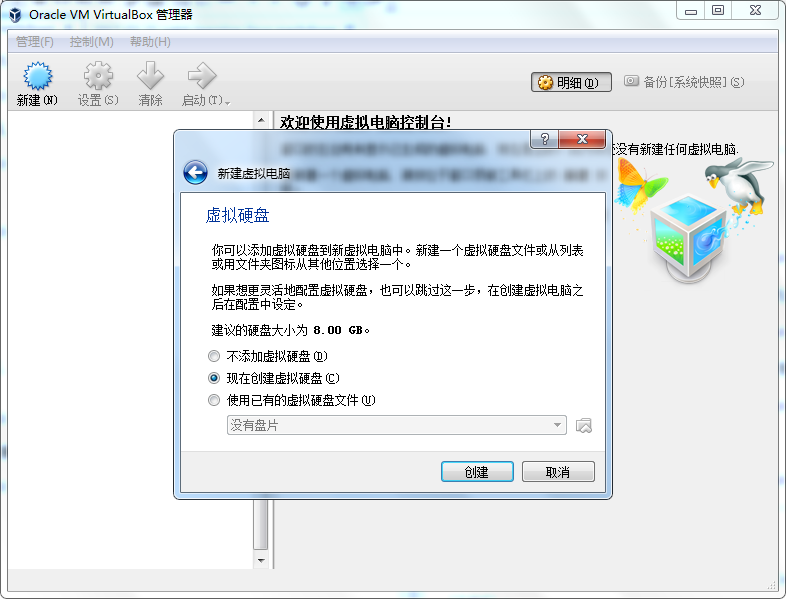
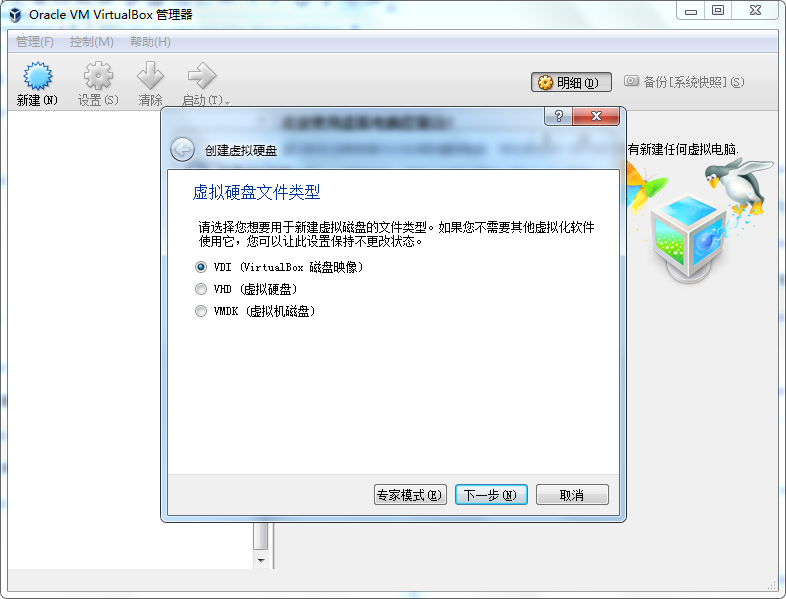
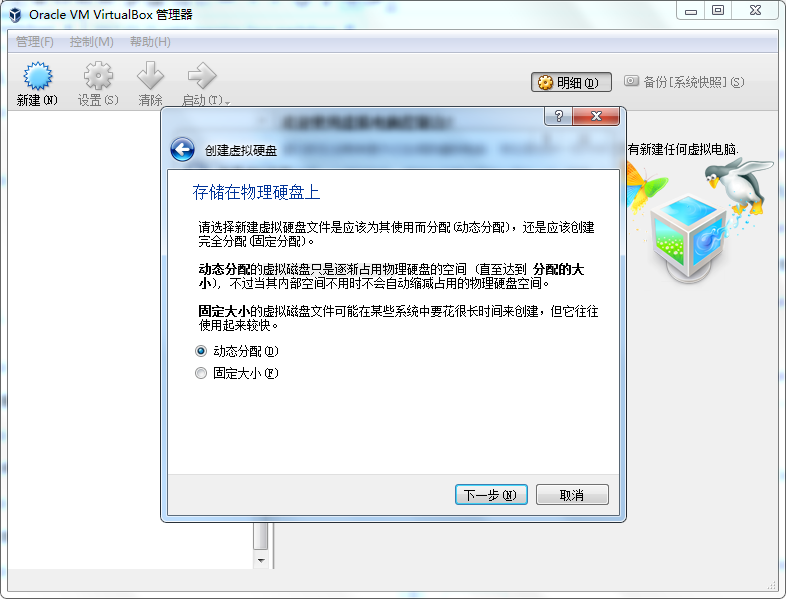
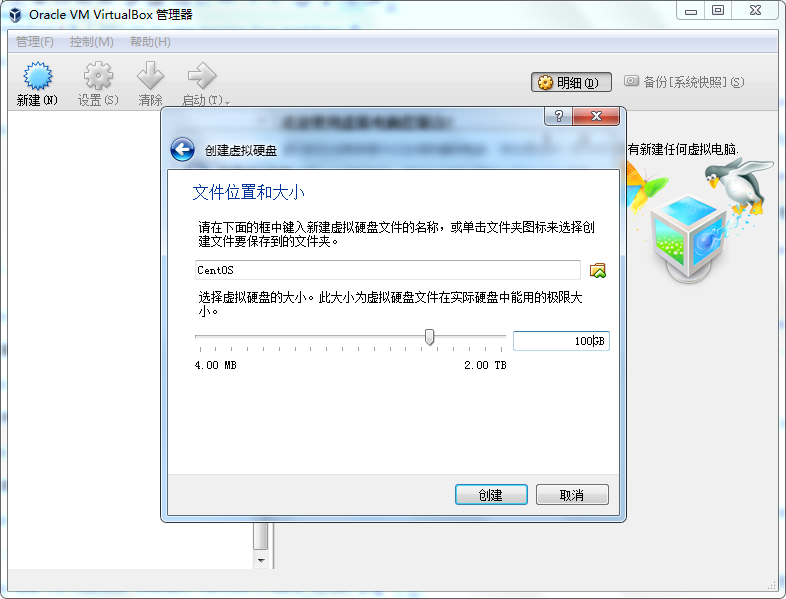
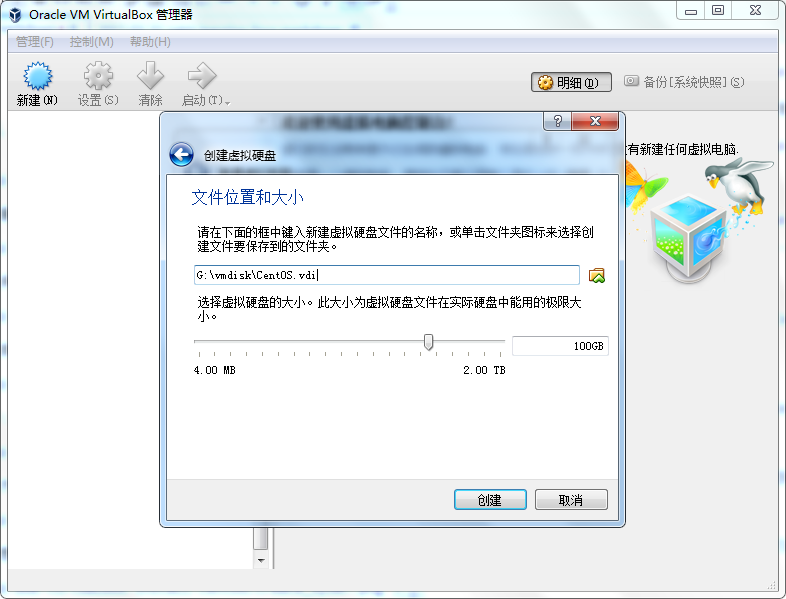
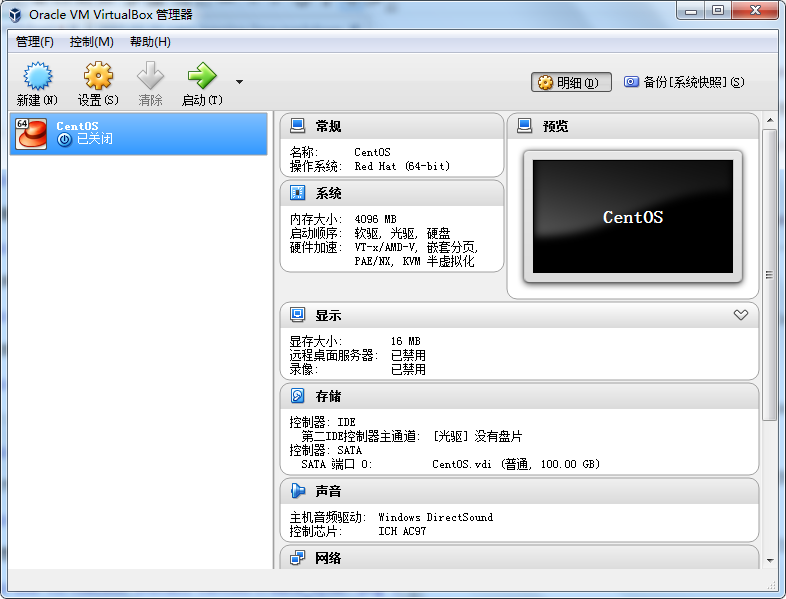
现在市面上比较流行的虚拟就有VMware,VirtualBox。由于VMware是收费的,而VirtualBox是开源免费的,就凭这一点,我们就选择使用VirtualBox了哈,当然除了开源免费外,它还要诸多优点的,比如它跨平台:可以运行在 Windows, Mac OS X 和 Linux/UNIX平台上,可以虚拟出我们常见系统等等,所以完全够我们使用。
早前 Red Hat公司 就发行了「Red Hat Linux」的个人版本,到了Red Hat 9.0版本后,Red Hat公司就不再发行桌面版的发行套件了,Red Hat Linux 也就停止了开发,而开始全力集中转向服务器版本上,也就是Red Hat Enterprise Linux(企业版本)。
后来 Red Hat Linux 的桌面版本与来自开源社区的Fedora进行合并,Red Hat Linux 桌面版就称为了 Fedroa Core。
所以目前Red Hat有:免费的Fedroa Core版本,也有收费的Red Hat Enterprise Linux版本。Red Hat Enterprise Linux都会在Fedroa Core版本的基础上进行升级,大约发布6个Fedroa Core版本就会发布一个Red Hat Enterprise Linux版本。
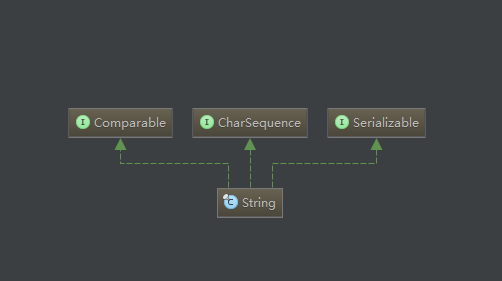
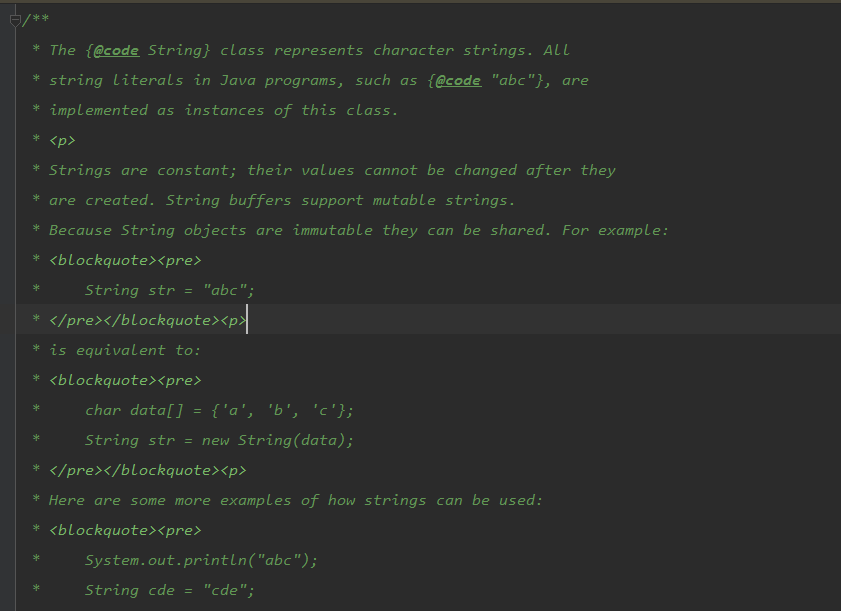
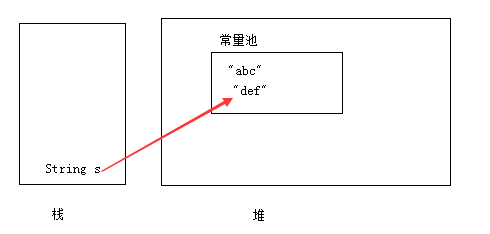
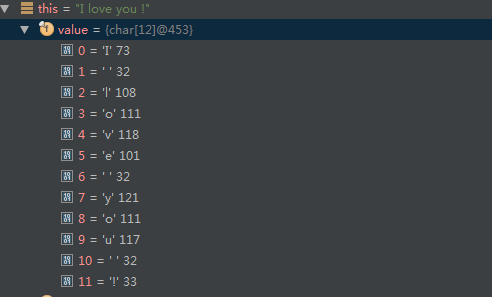
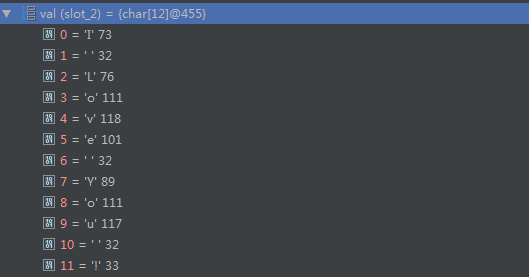
通过 debug 可以看到其实我们刚刚定义的 String msg = “I love you !” 中的值被放到了 value 这个数组中了!
String
而我们 char c = msg.charAt(3) 传入的这个3 就是这个数组对应的下标3,所以呢,输出就是o啦!
String
equals(Object anObject)
equals我们通常用于比较是否相同,那么你知道下面这段代码分别输出的是什么吗?
1 2 3 4 5 6 7
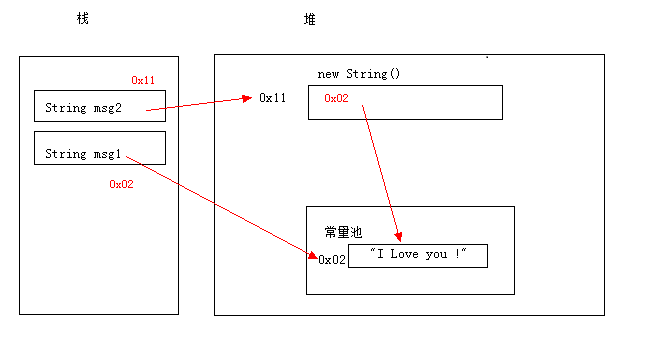
String s = "I Love You !"; String s1 = "I Love You !"; String s2 = new String("I Love You !"); System.out.println(s == s1); System.out.println(s.equals(s1)); System.out.println(s == s2); System.out.println(s.equals(s2));
他们分别输出的:
true
true
false
true
可能有些人会奇怪会什么 s == s2 是false? 他们不是都是是 “”I Love You !” 吗? 这时候我们就要来看看 == 和 equals 的区别了!
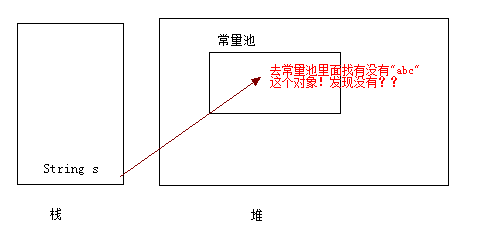
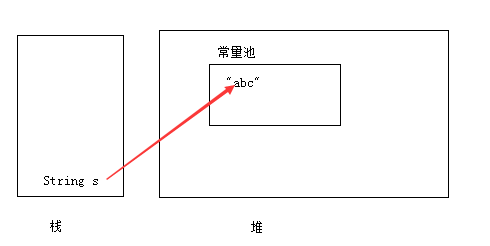
其实 == 比较的是他们的地址值(hashcode),我们知道String是不可变的,我们可以知道s 和 s1 指向的都是 “I Love You !”;所以他们的hashcode是一样的。所以返回true;而s 和 s2 他们指向的地址是不一样的所以是false;






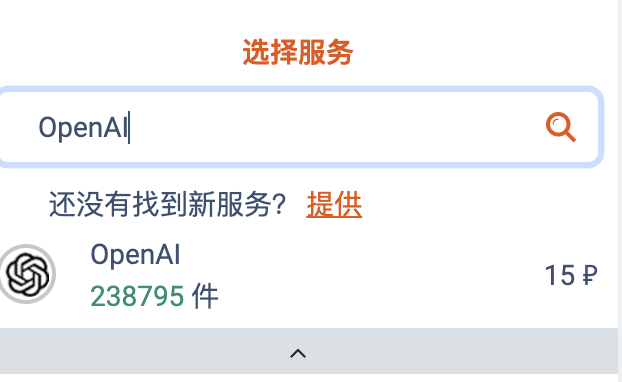

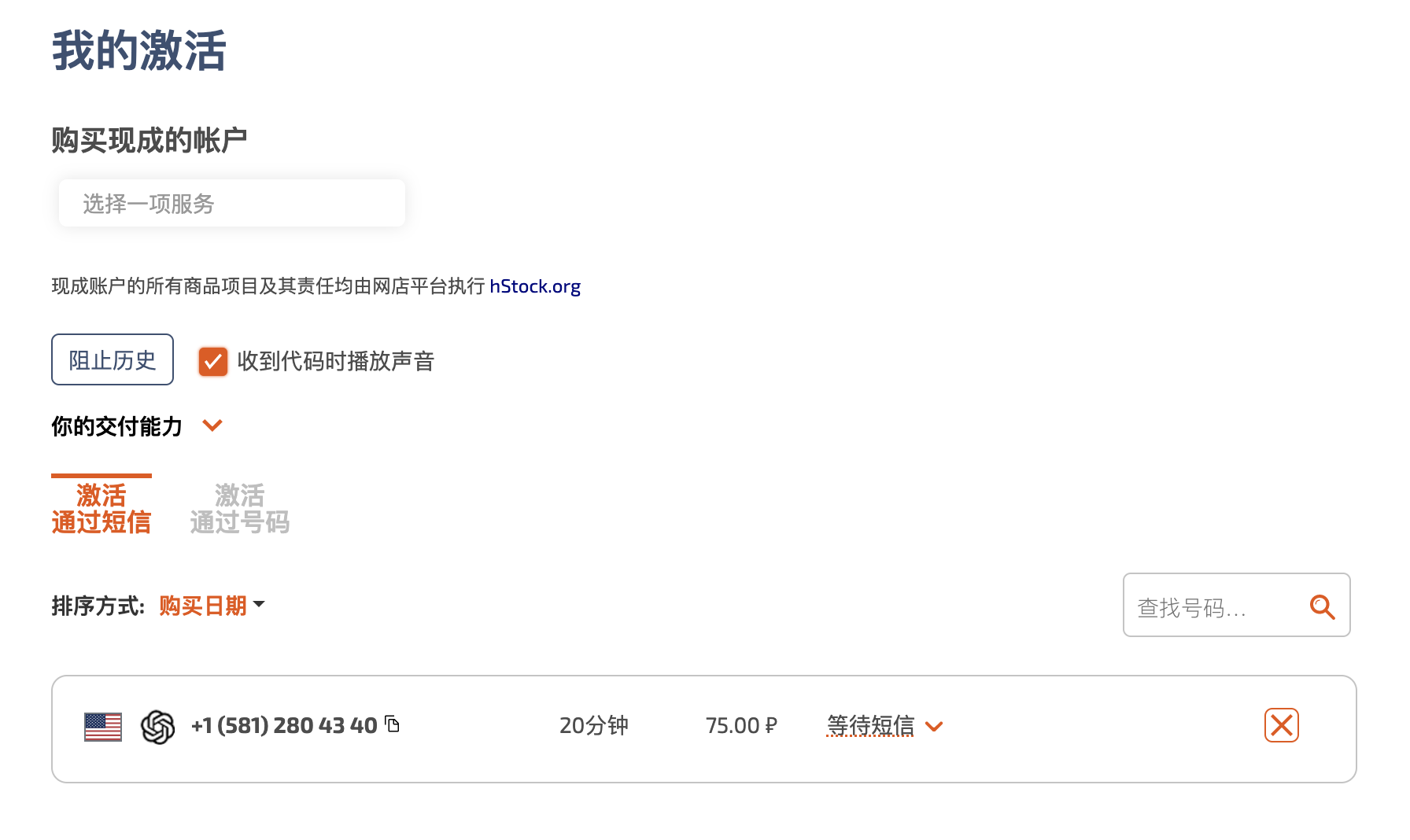
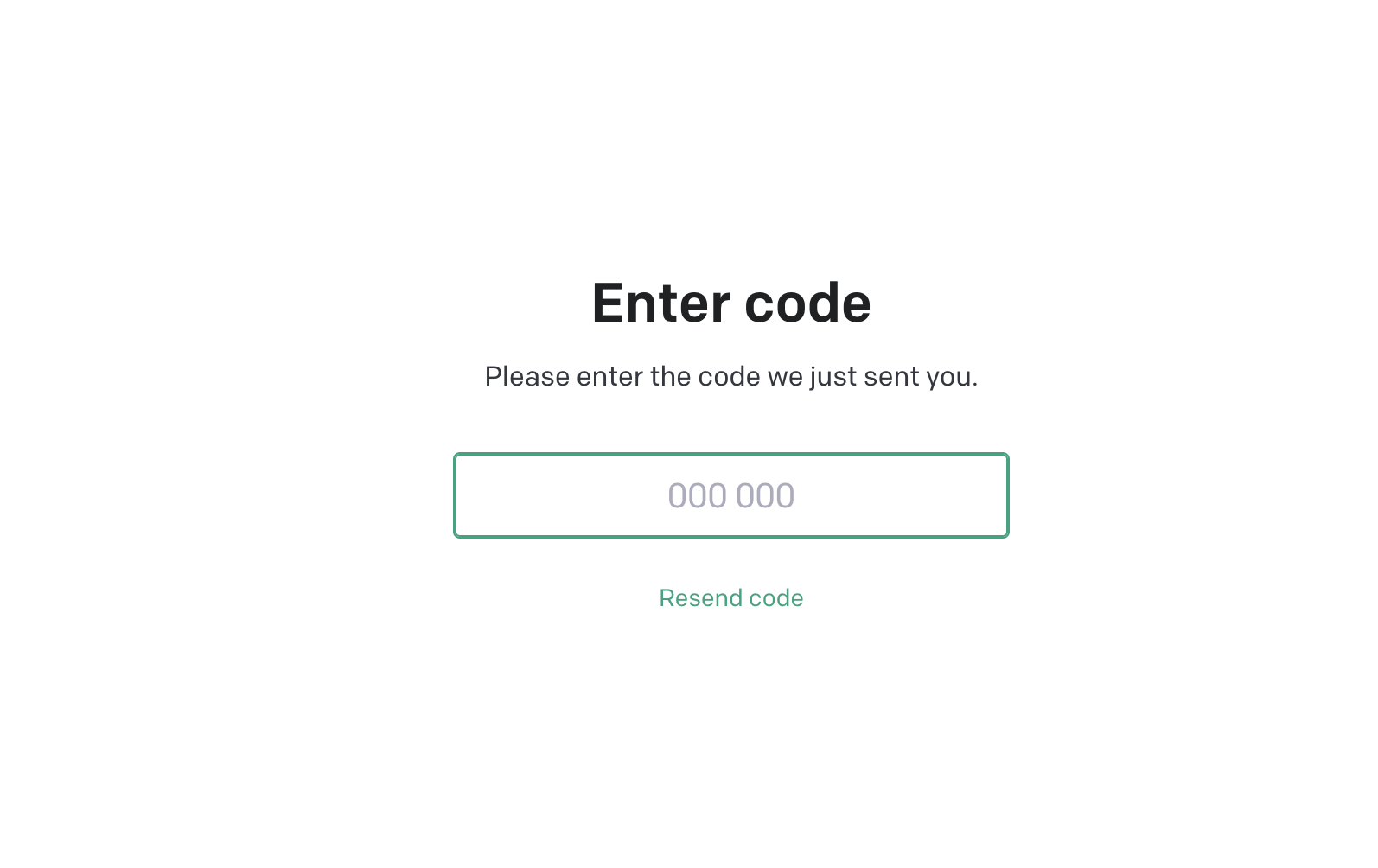
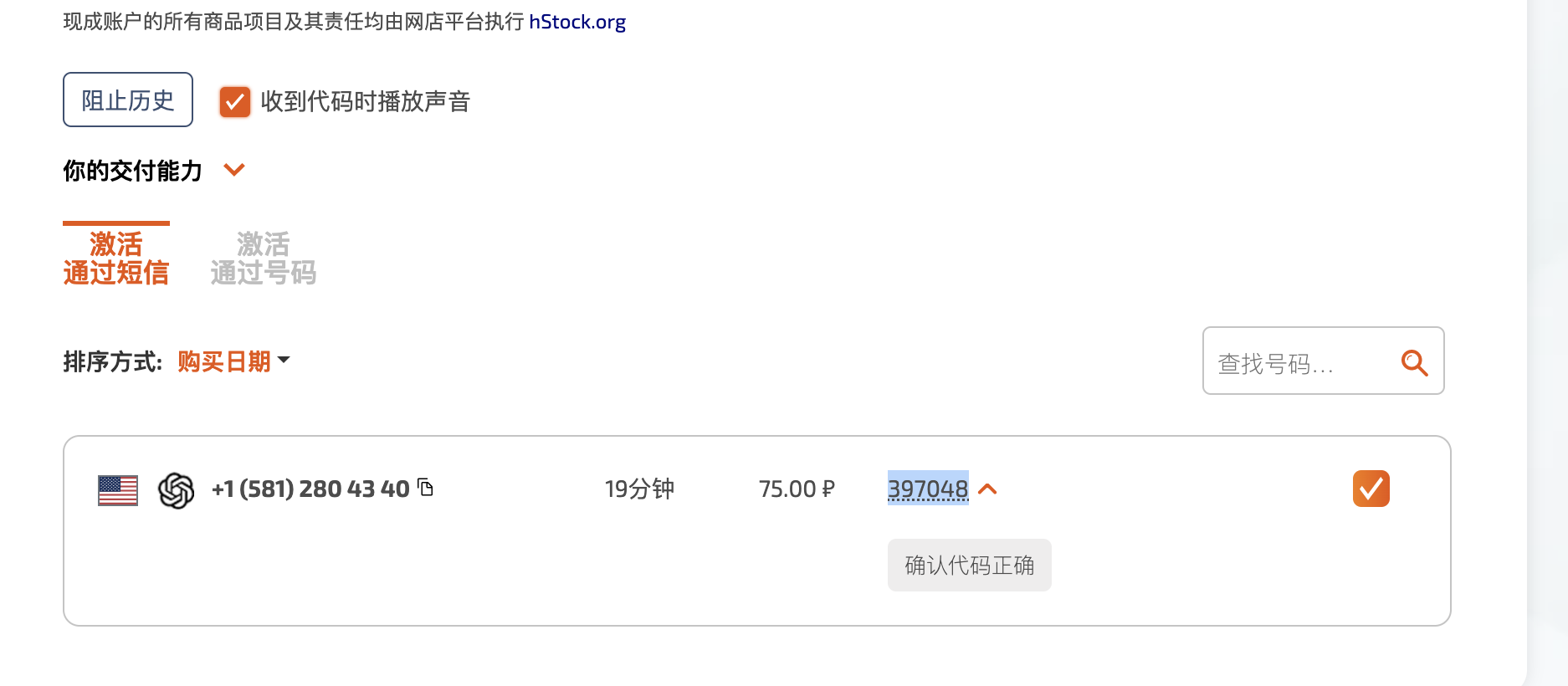













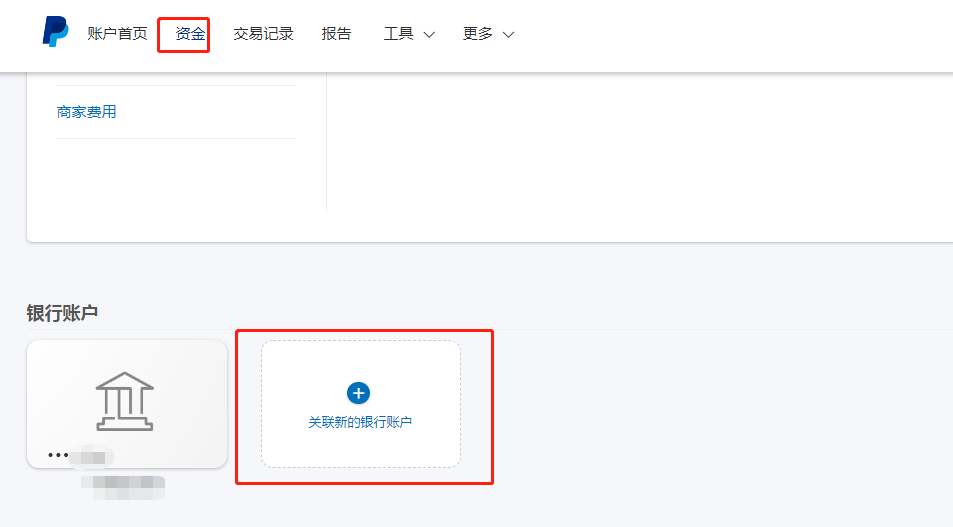
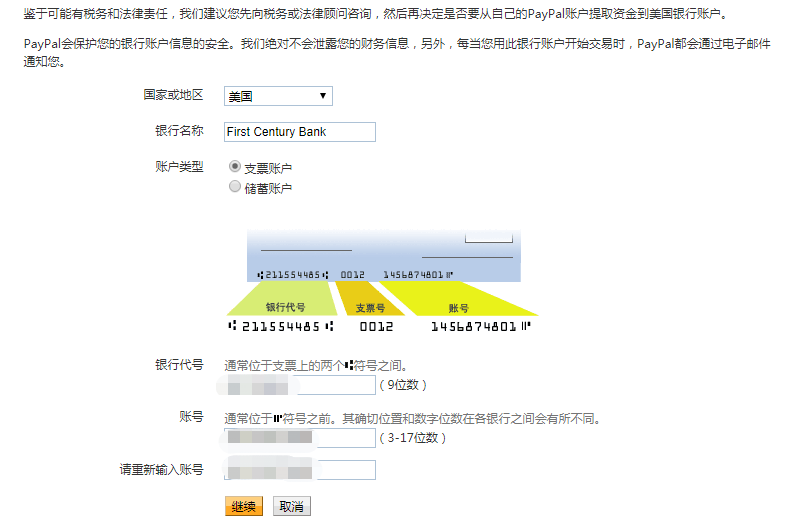
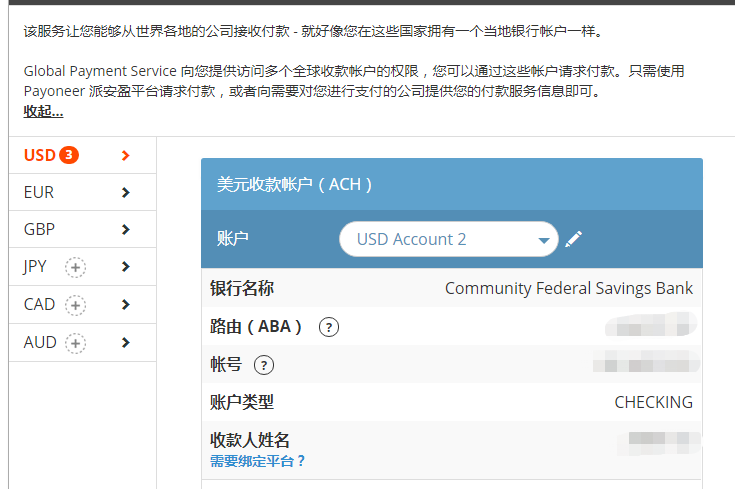
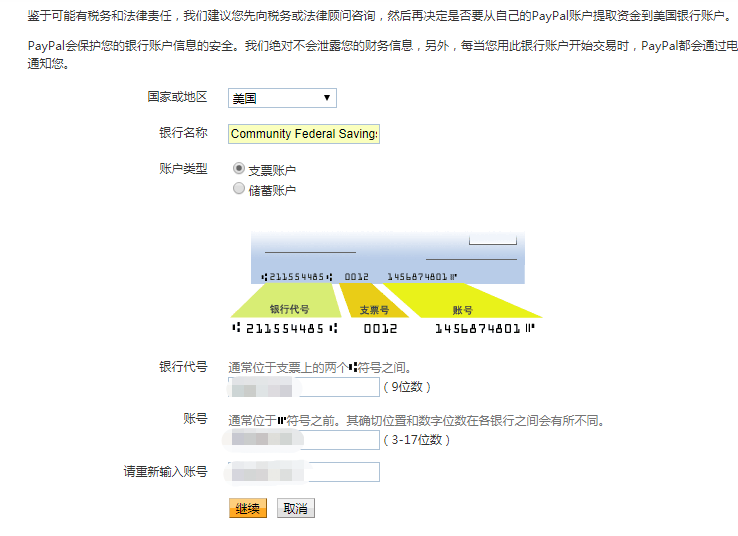
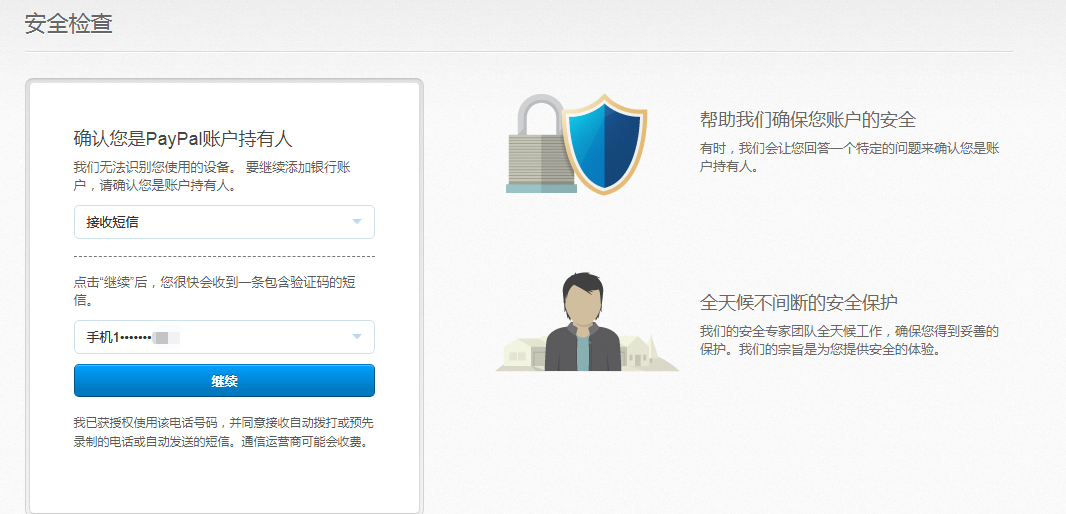
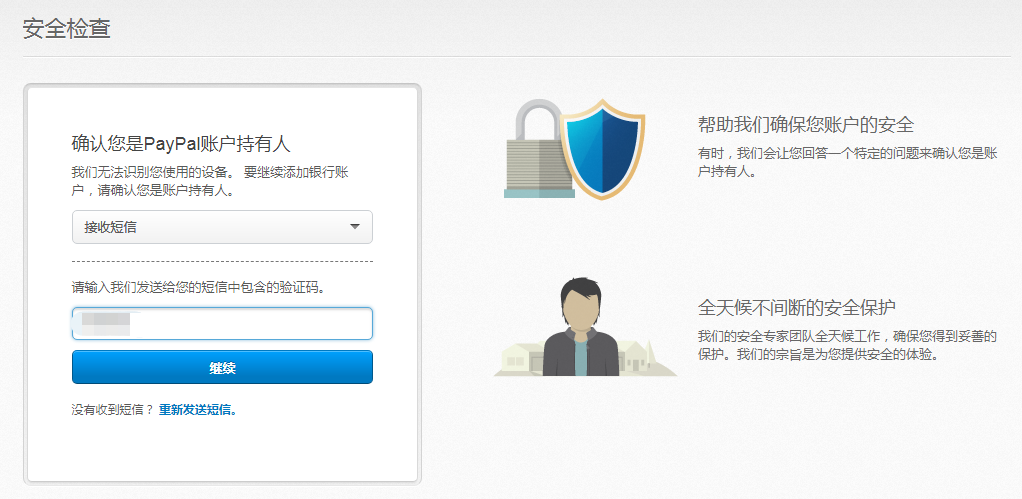
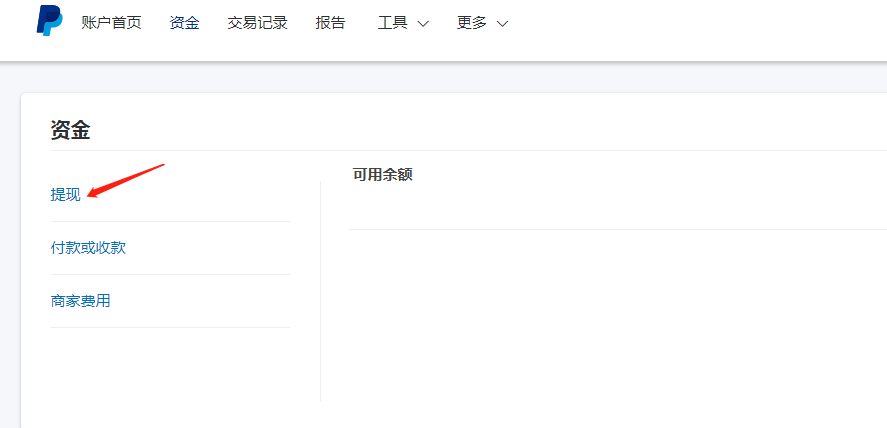
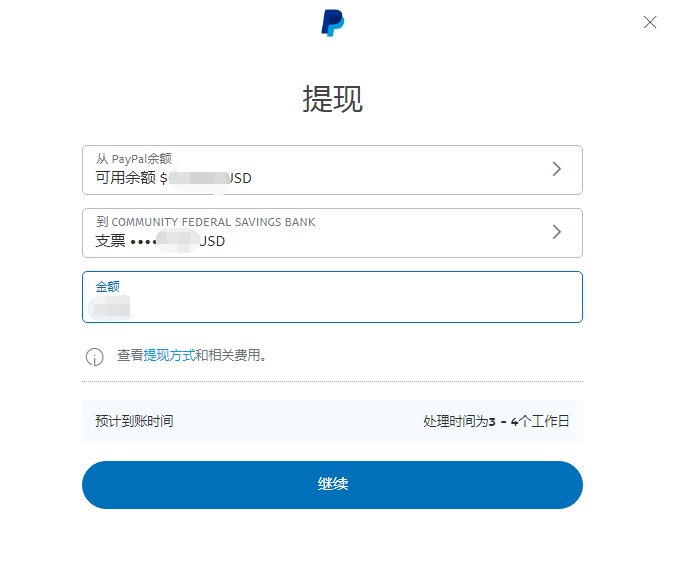
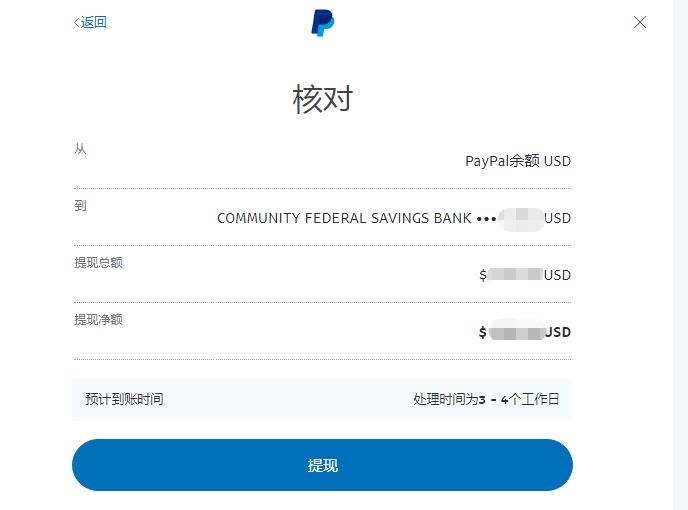
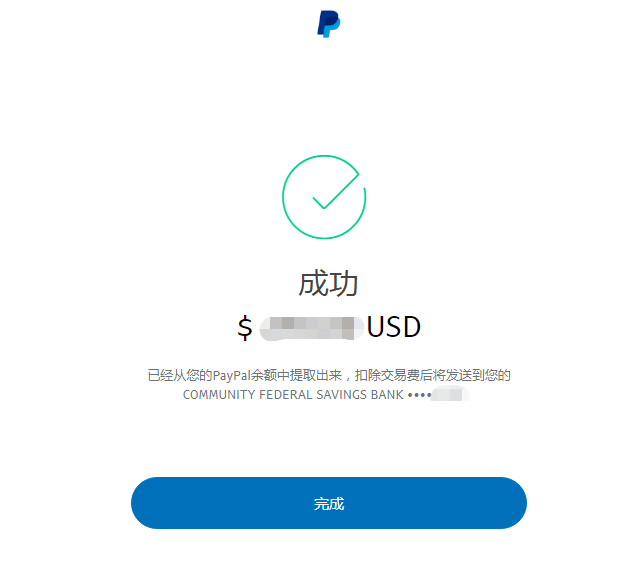
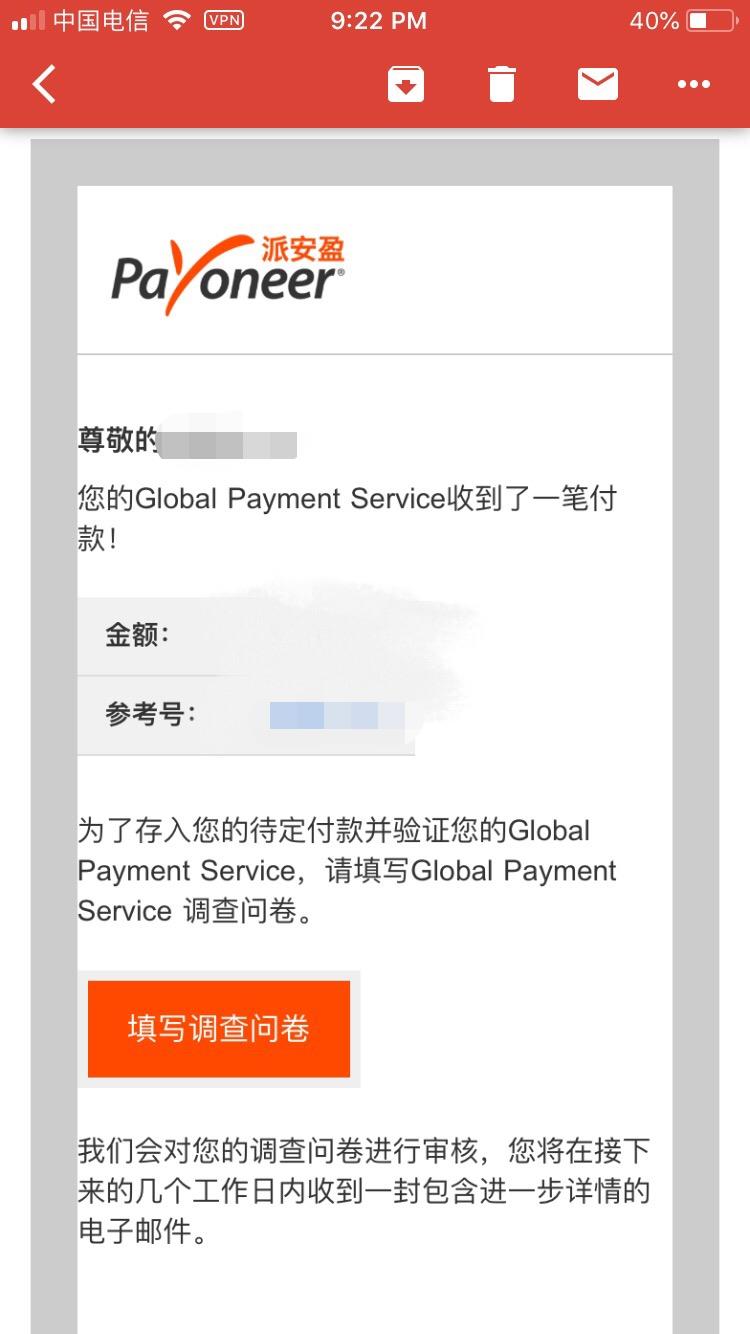
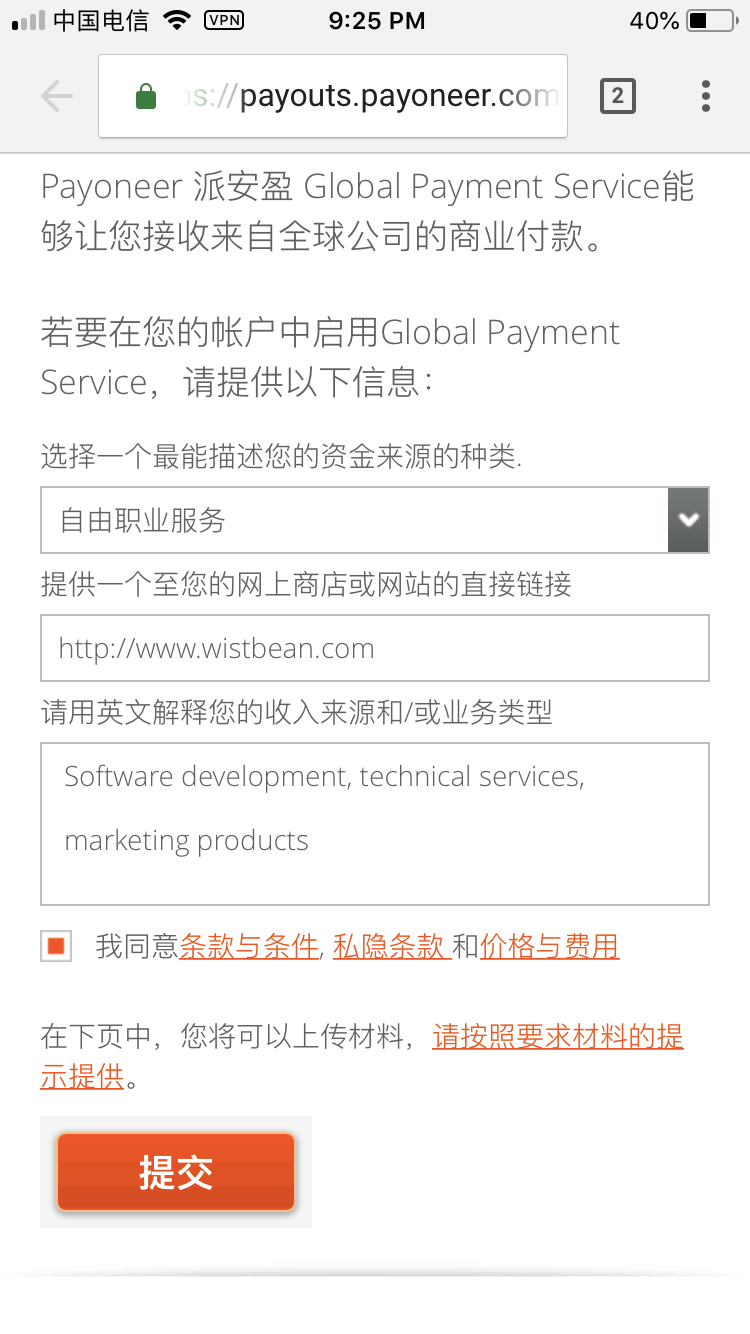
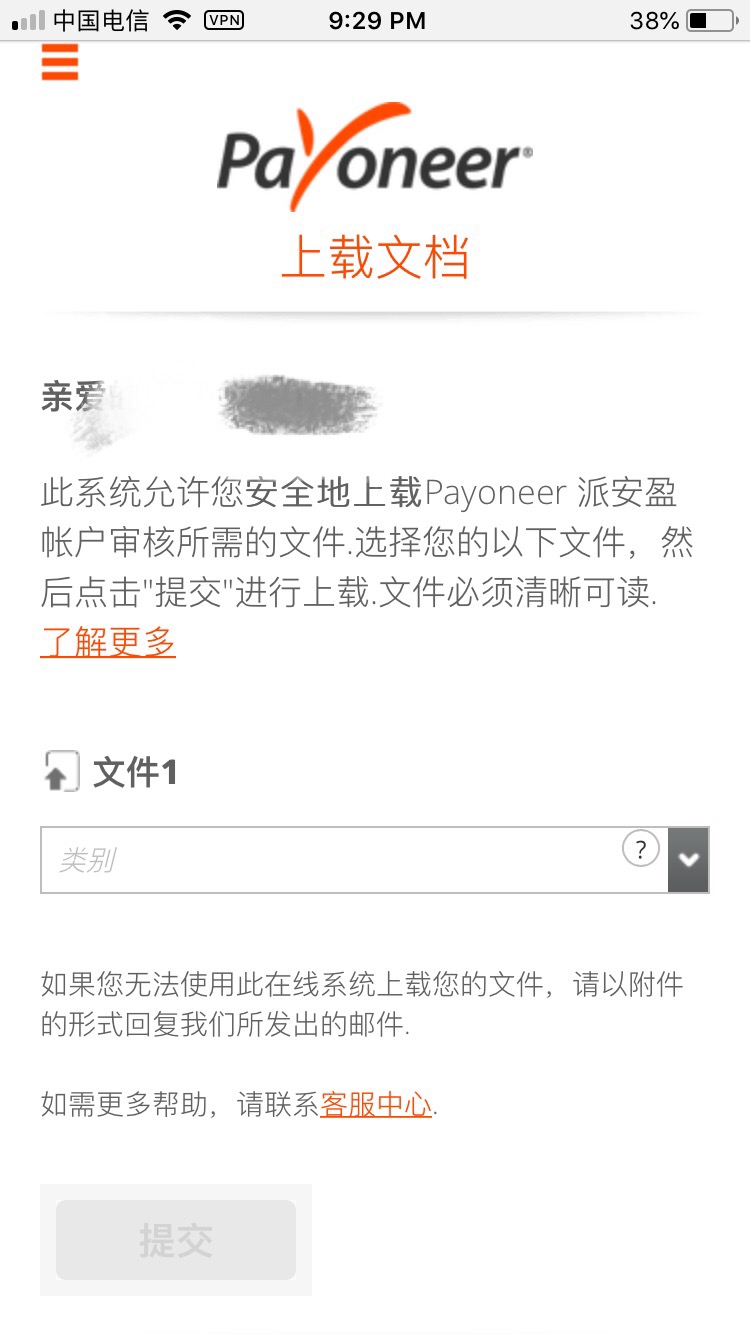
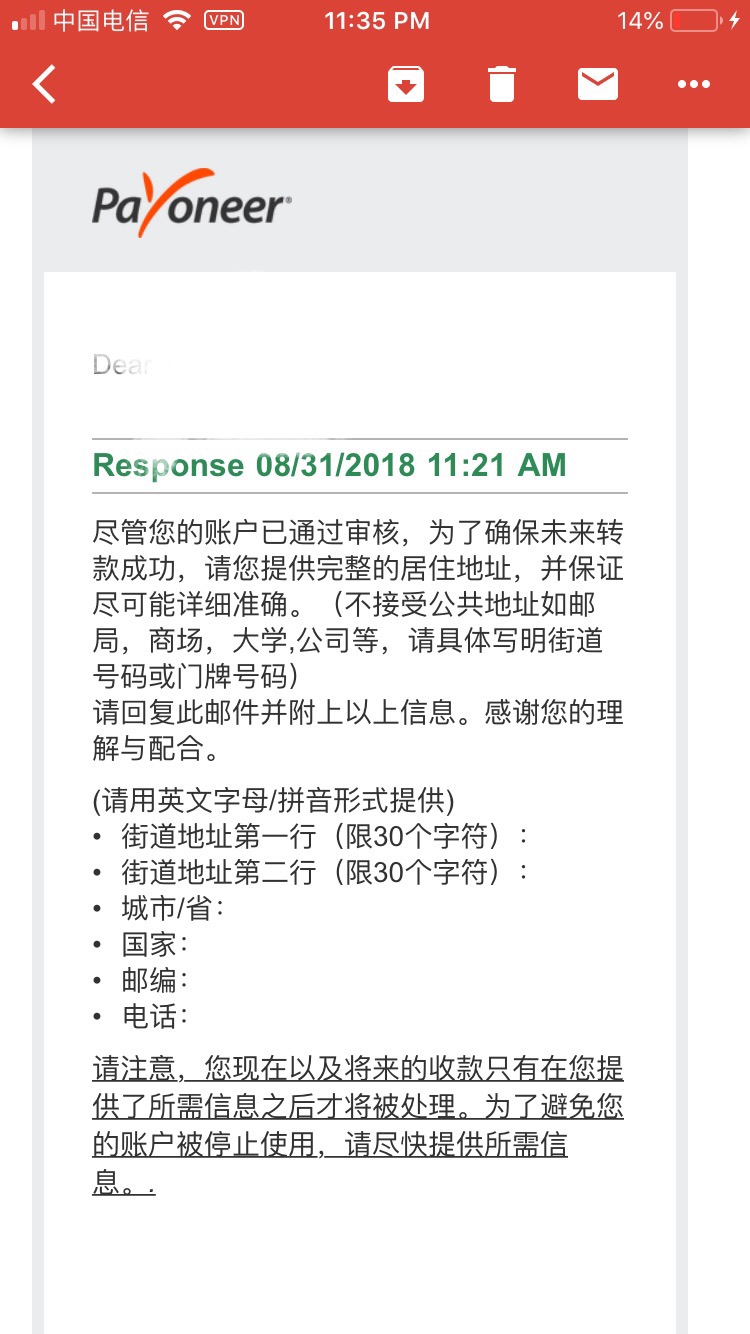
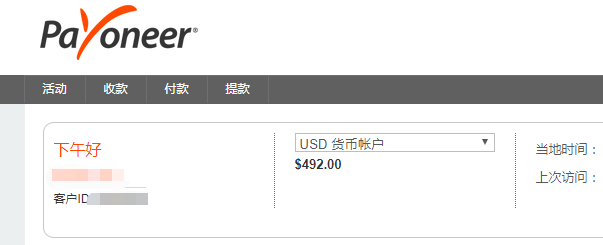
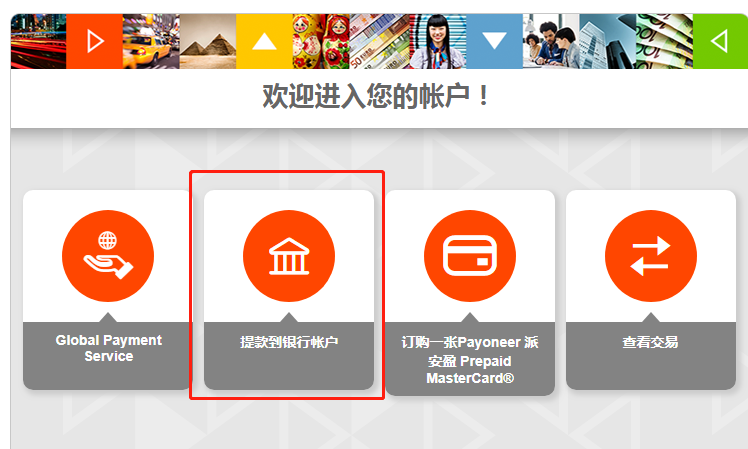








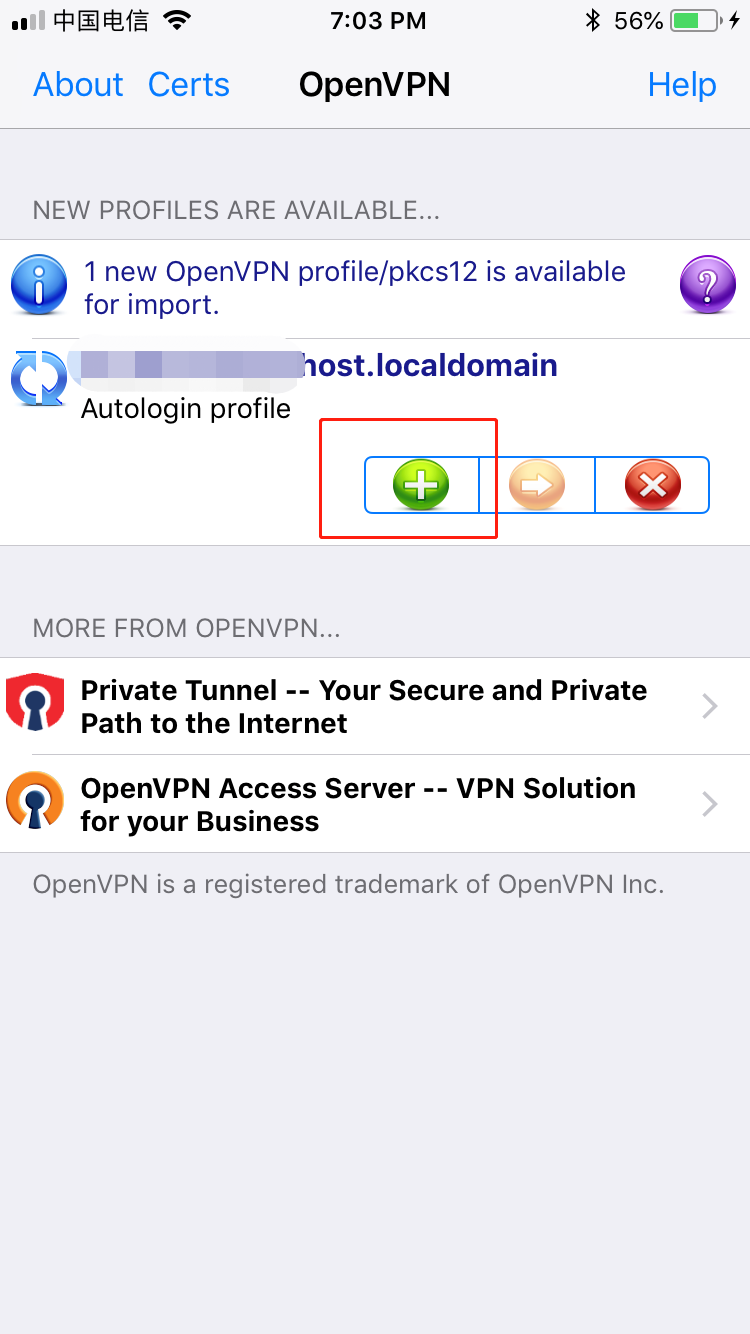
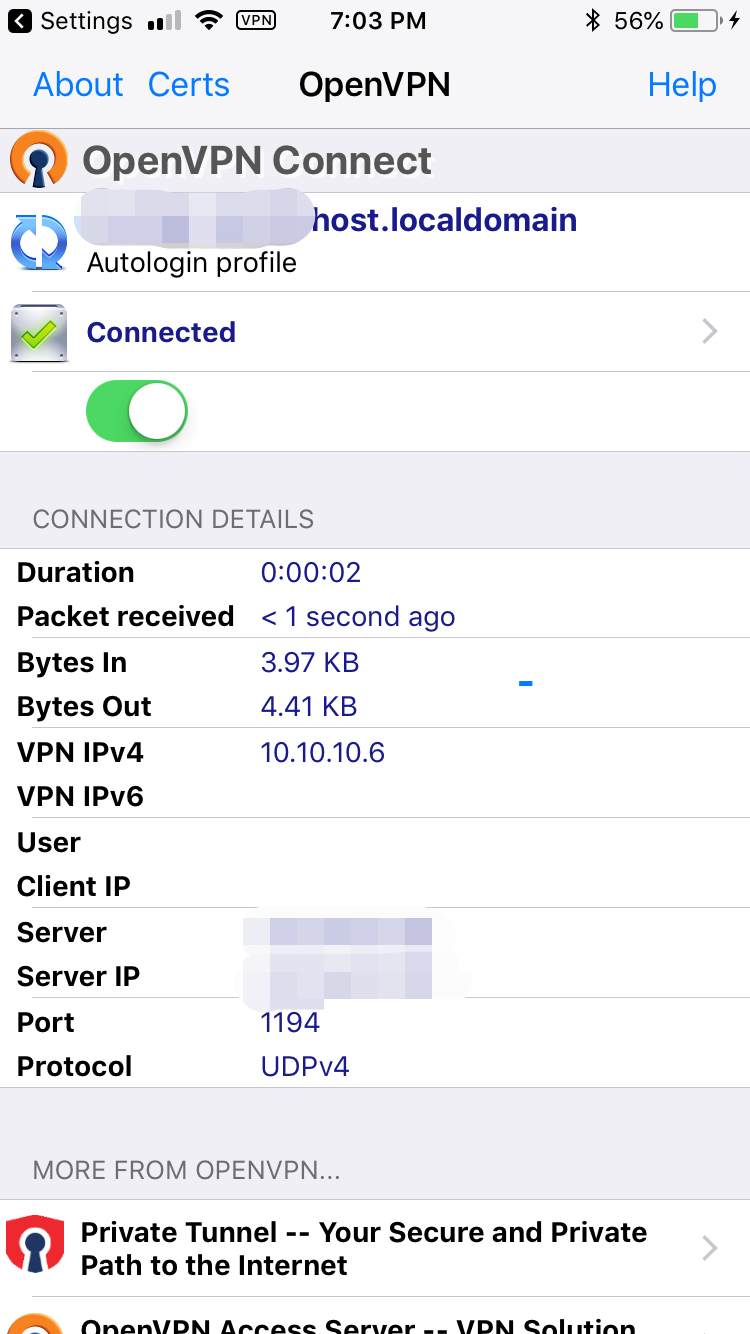

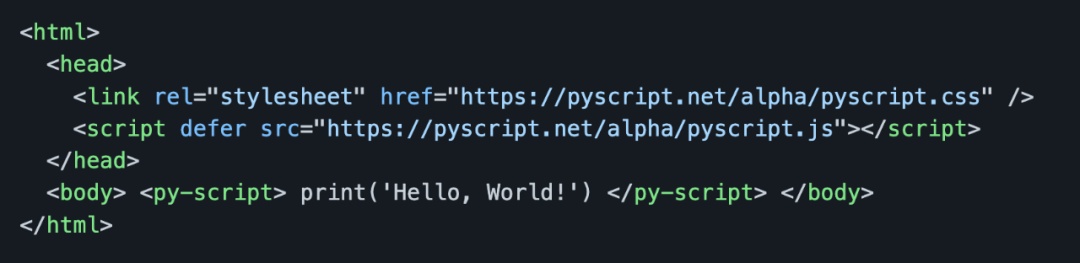




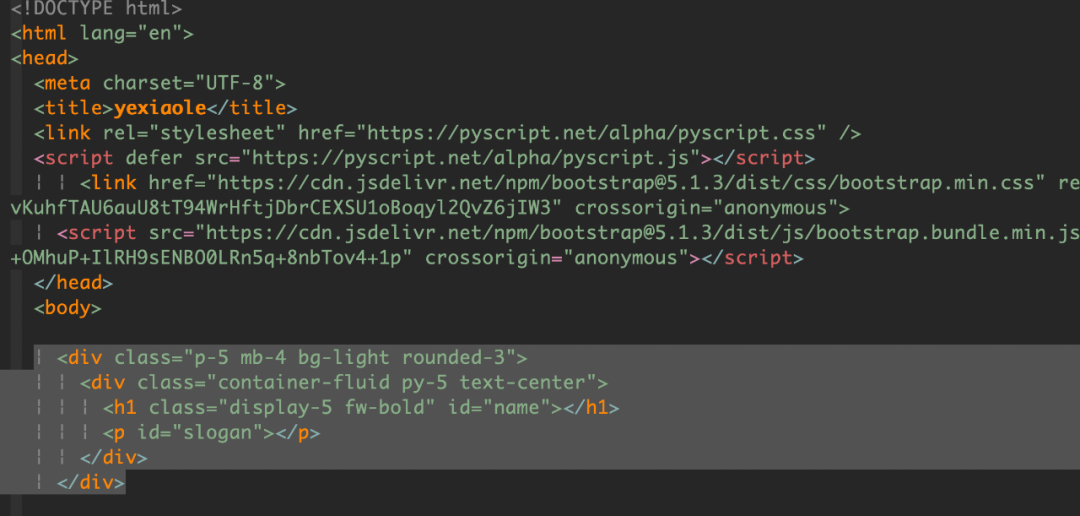
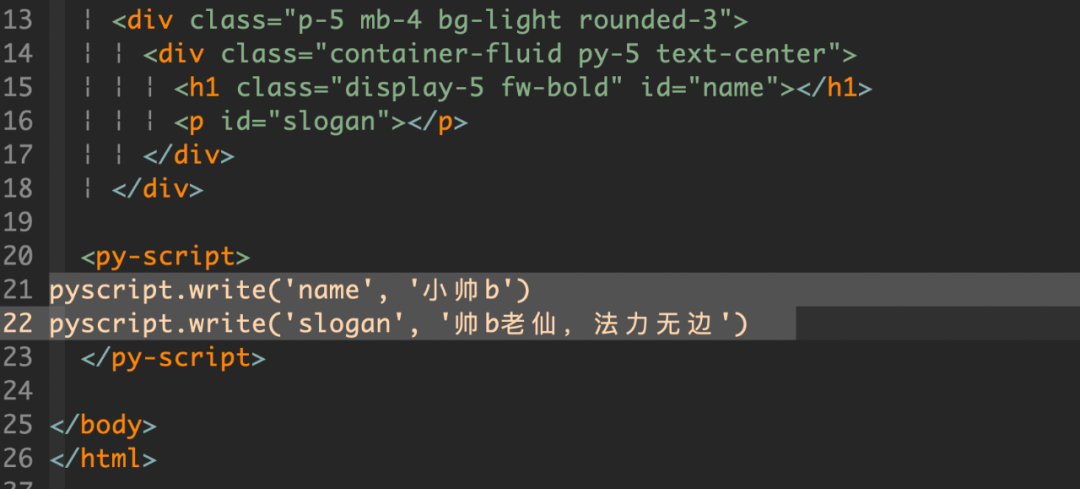


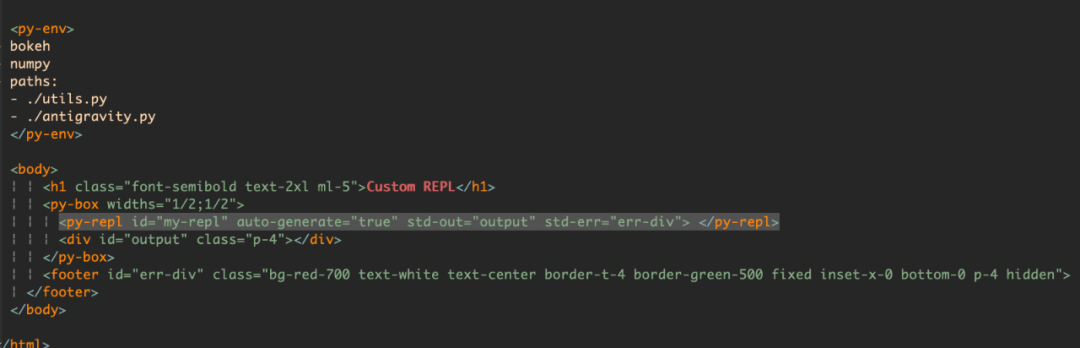
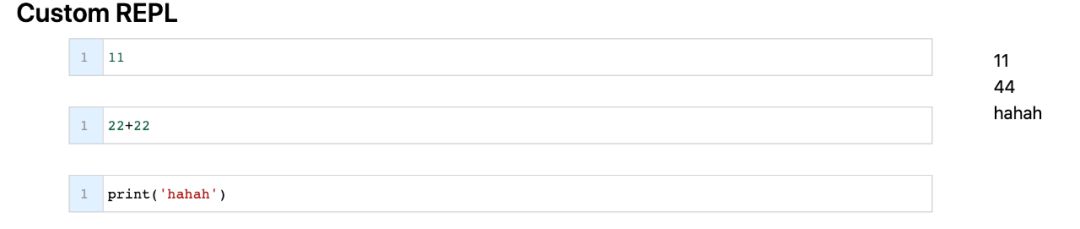























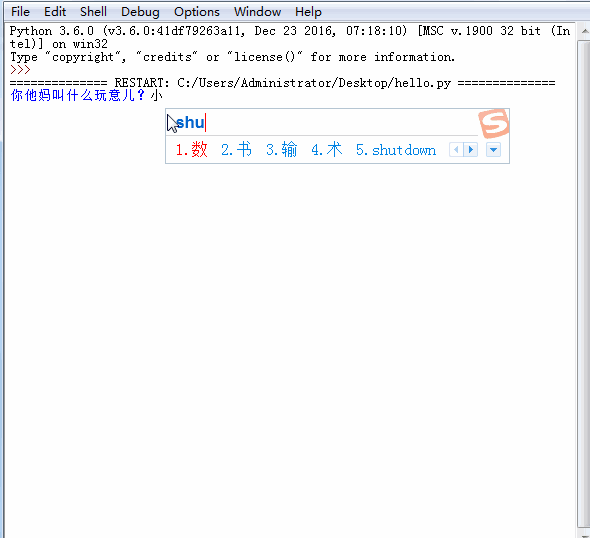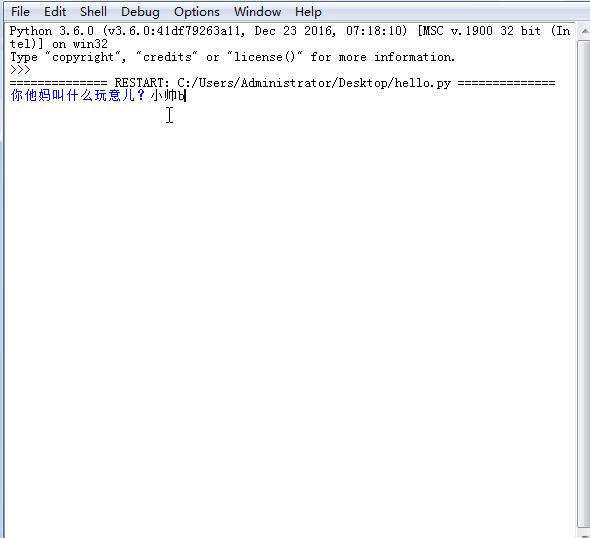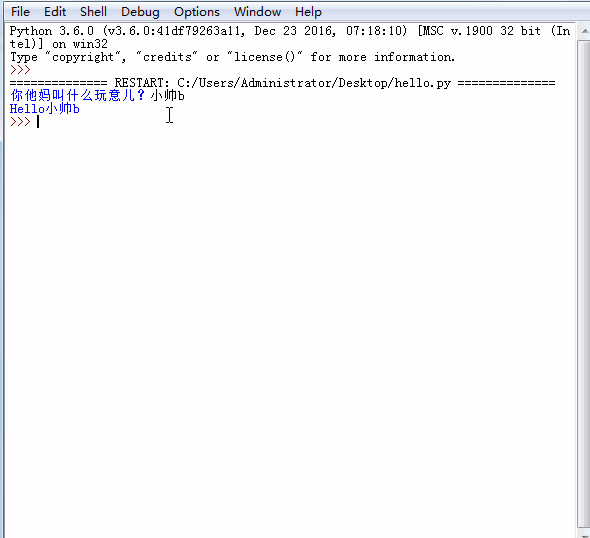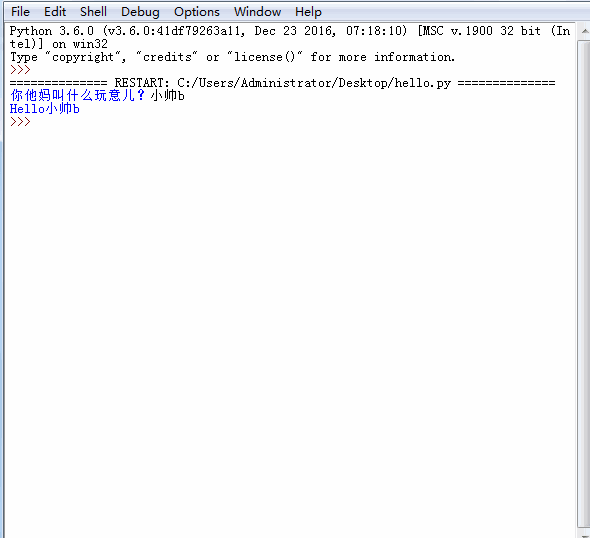















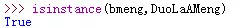

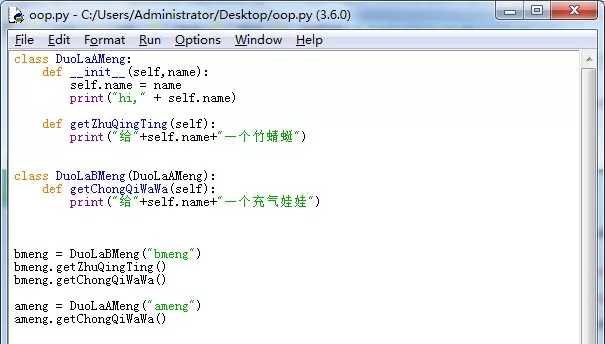
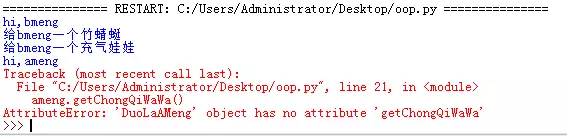












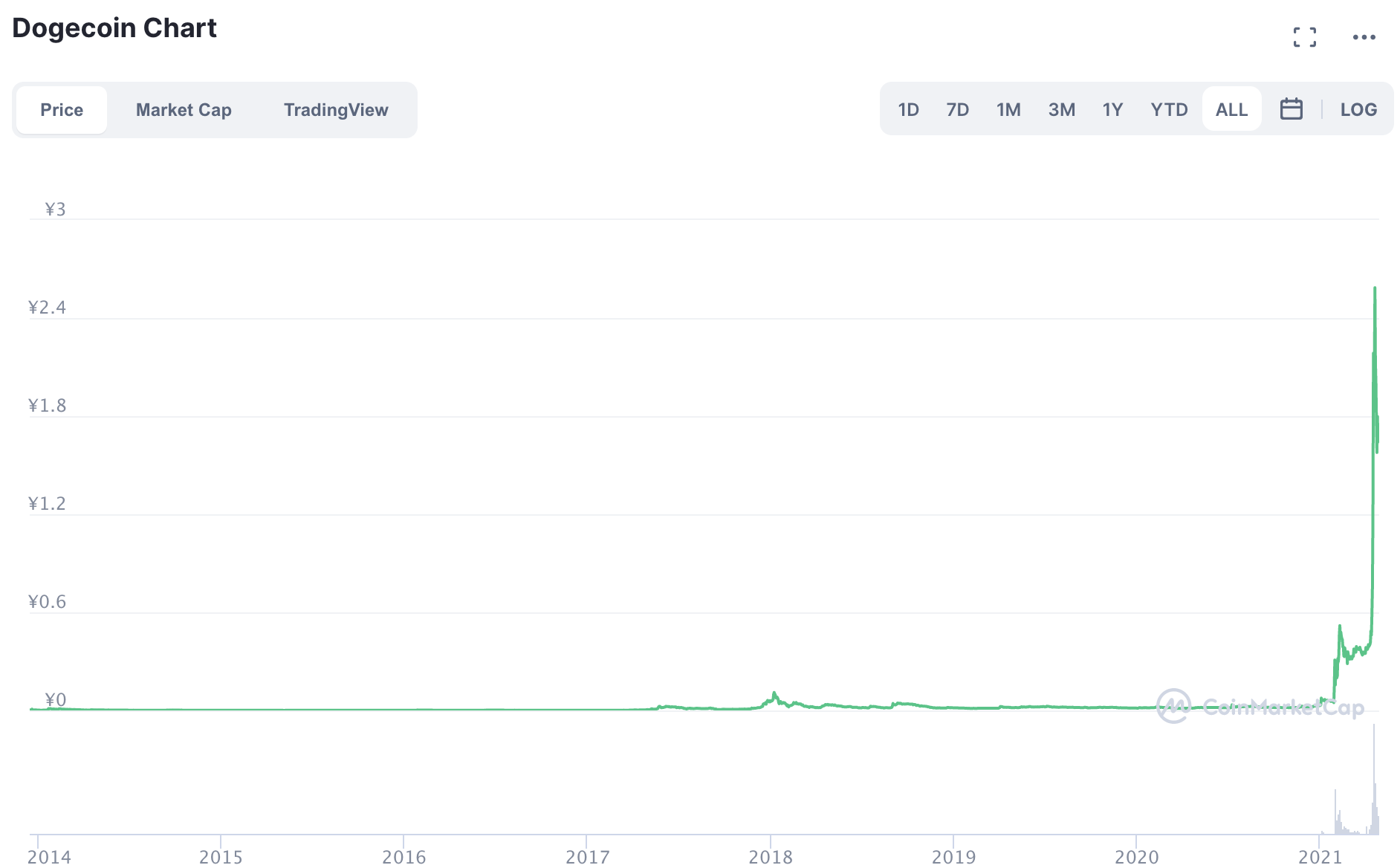




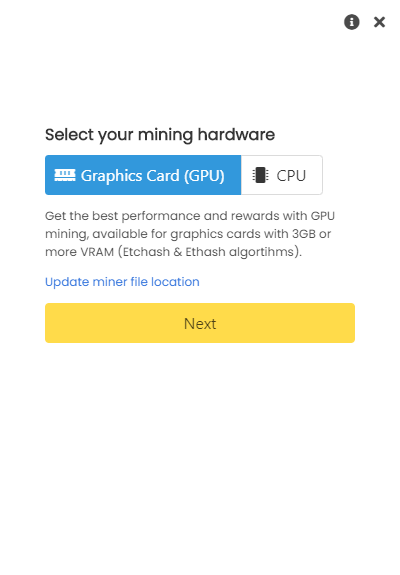
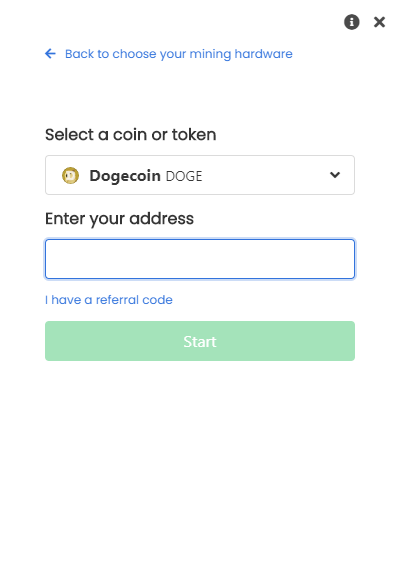
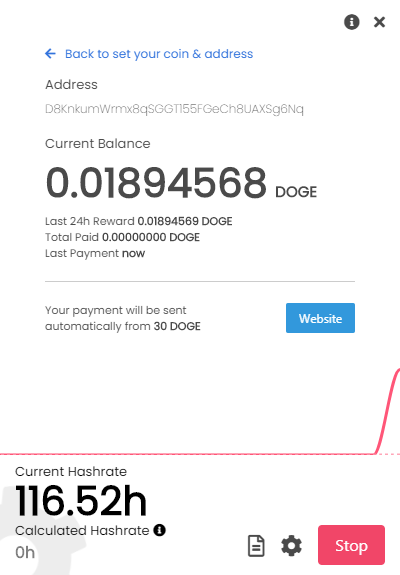






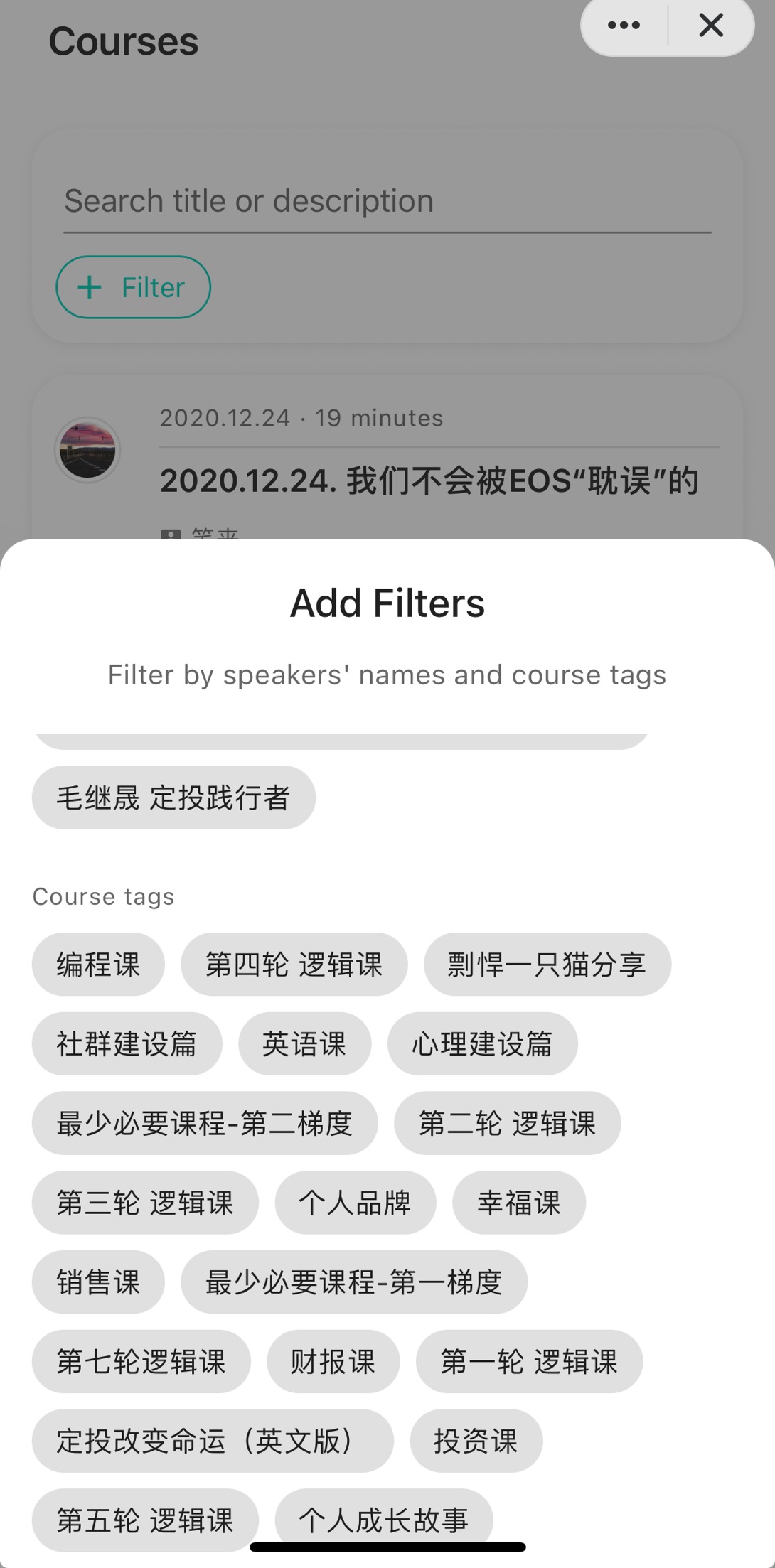
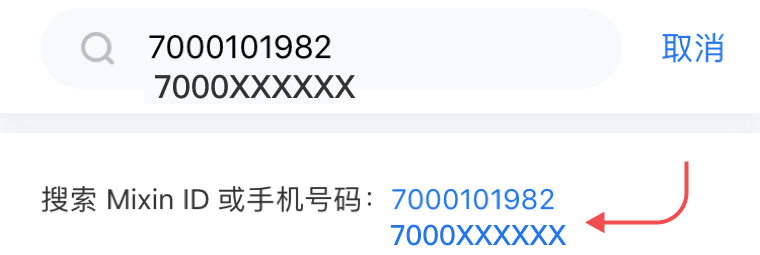
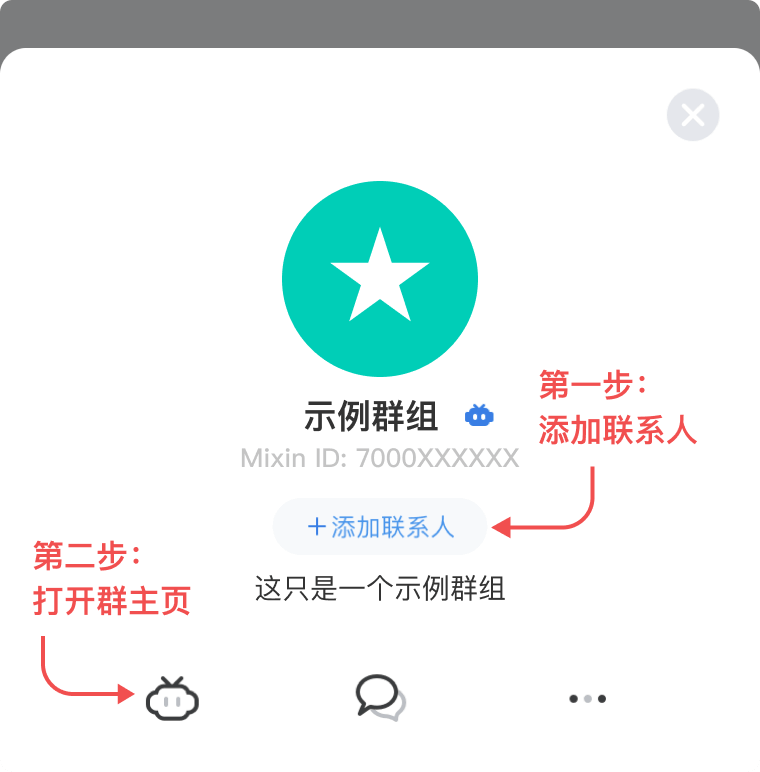
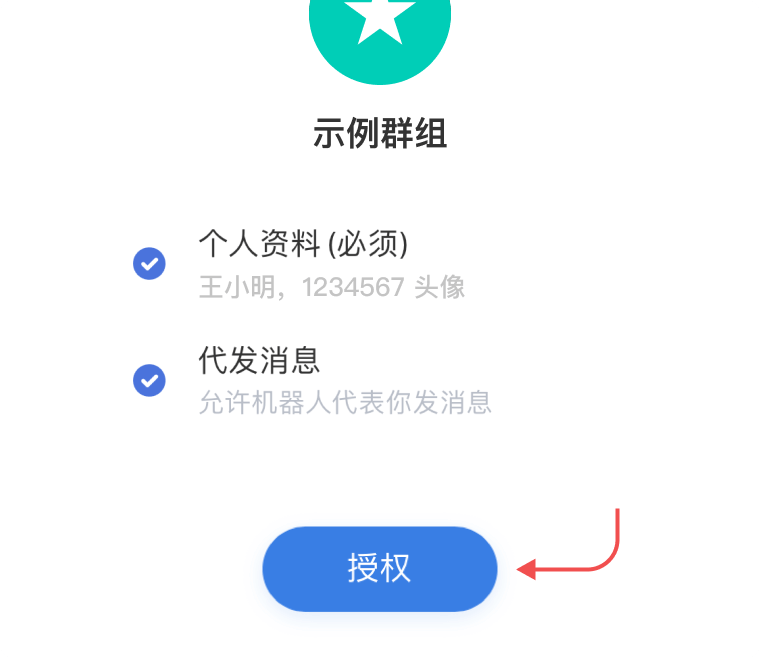
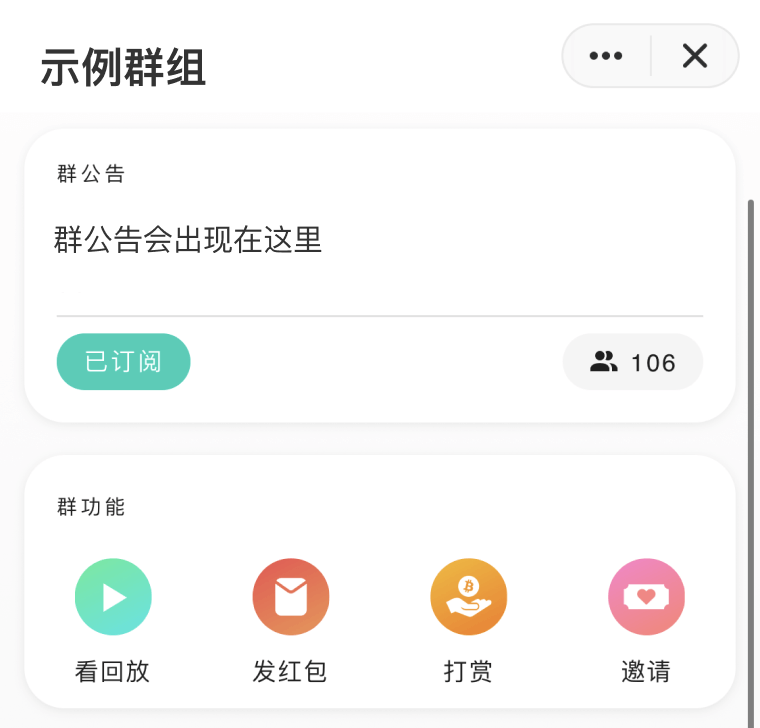






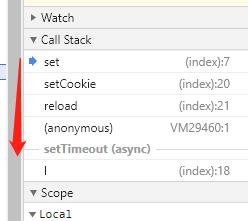
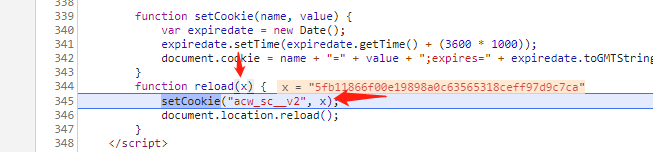
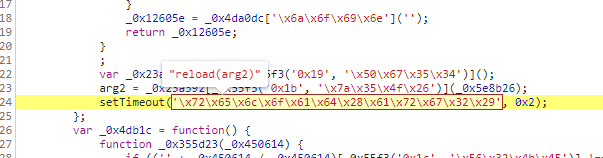
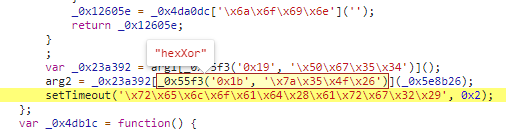
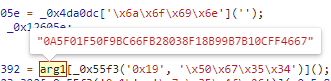
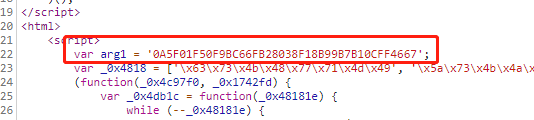
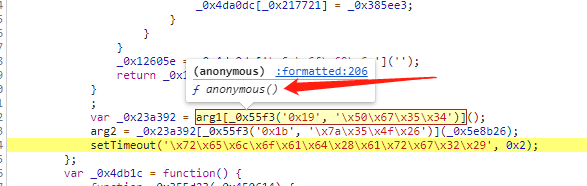
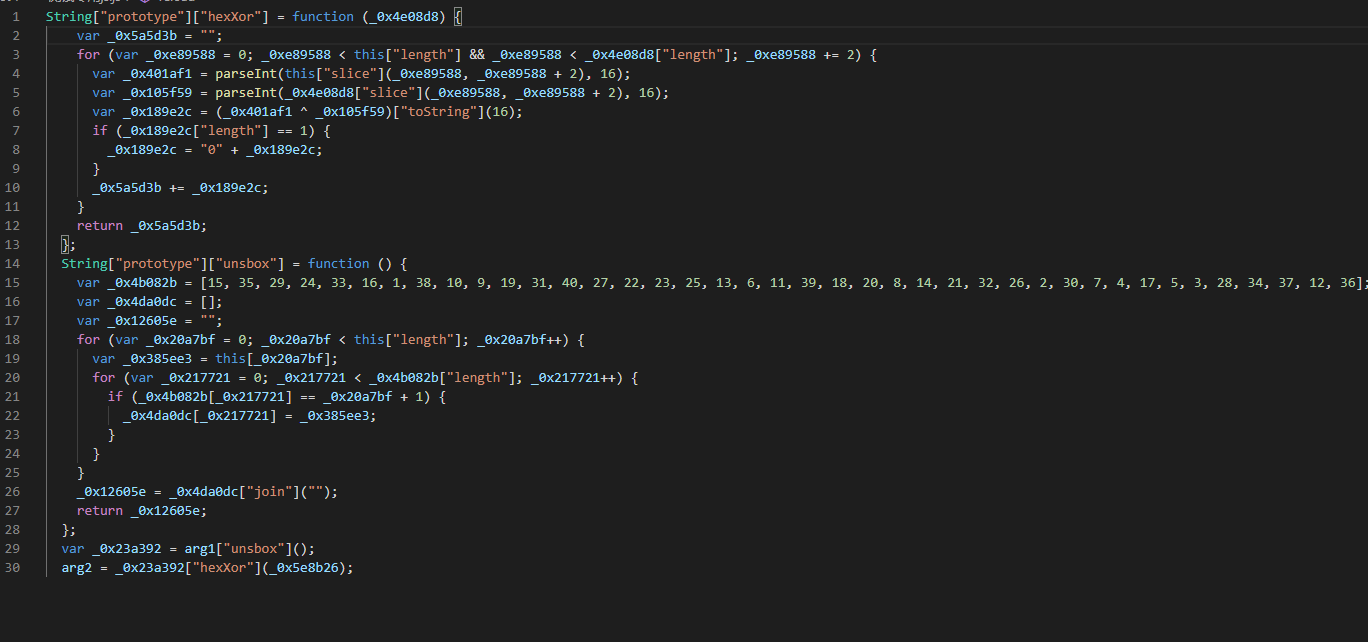





































































































































































































































































































































































































































































 ,点个
,点个





















































































































































































































































































































































































































{kind=link}